
KI für Autor:innen

Bei der Criminale 2025 in Schwetzingen durfte ich einen Vortrag zum Thema "KI für Autor:innen" halten: Was kann das schon? Was noch nicht? Und sollten wir als Autor:innen damit arbeiten?
Kurzfassung: Das kommt drauf an.
Vorbemerkung: Es gibt eine Schwemme von Modellen für allerlei Anwendungsfälle. In diesem Artikel behandle ich welche, mit denen ich persönlich schon Erfahrungen gesammelt habe. Die Liste an Modellen und Quellen hier ist also weder vollständig noch objektiv, sondern rein meinem Erfahrungsschatz geschuldet. (Eine von Menschen gepflegte Liste an aktuellen Modellen findet Ihr zB bei Cogneon.) Meine Perspektive auf das Thema ist einerseits die einer freiberuflichen Autorin, die von ihrem geistigen Eigentum lebt, aber auch die einer ausgebildeten Datenschutzbeauftragten mit Fortbildungen in IT-Security und ethical Hacking. Ihr werdet hier also keinen Marketing-Jubel lesen, warum ihr alle die neuen Sytsme zwingend verwenden müsst und sonst nie wieder einen Cent verdienen werdet. Ihr werdet hier auch keine Anleitung bekommen, wie man in einer Woche ein Buch mit KI schreibt! Falls ihr solch einen Artikel sucht, macht die Seite bitte gleich wieder zu, dieser Artikel ist nicht für euch. Alles hat seinen Rattenschwanz und den möchte ich hier auch herausstellen.
Generelles
Die Ergebnisse sind oft reine Wegwerf-Ware: Gefällt etwas nicht oder hat es sich überlebt, wird einfach schnell ein neuer Text, ein neues Bild oder eine ganze neue Marketing-Kampagne generiert. Die Produkte haben nicht selten den Charme von Plastikbesteck und einen vergleichbaren ökologischen Fußabdruck. Dennoch sind wir mitten im Hype-Cycle. Und der wird voraussichtlich auch noch eine Weile anhalten. Wir Autor:innen und Kreative hängen irgendwo zwischen "wir werden in drei Jahren alle arbeitslos sein", "wir werden alle doch nicht arbeitslos sein weil da eine Menge Müll generiert wird" und "die Welt wird von Müll geflutet sein und wir werden in einer völlig anderen Welt leben".
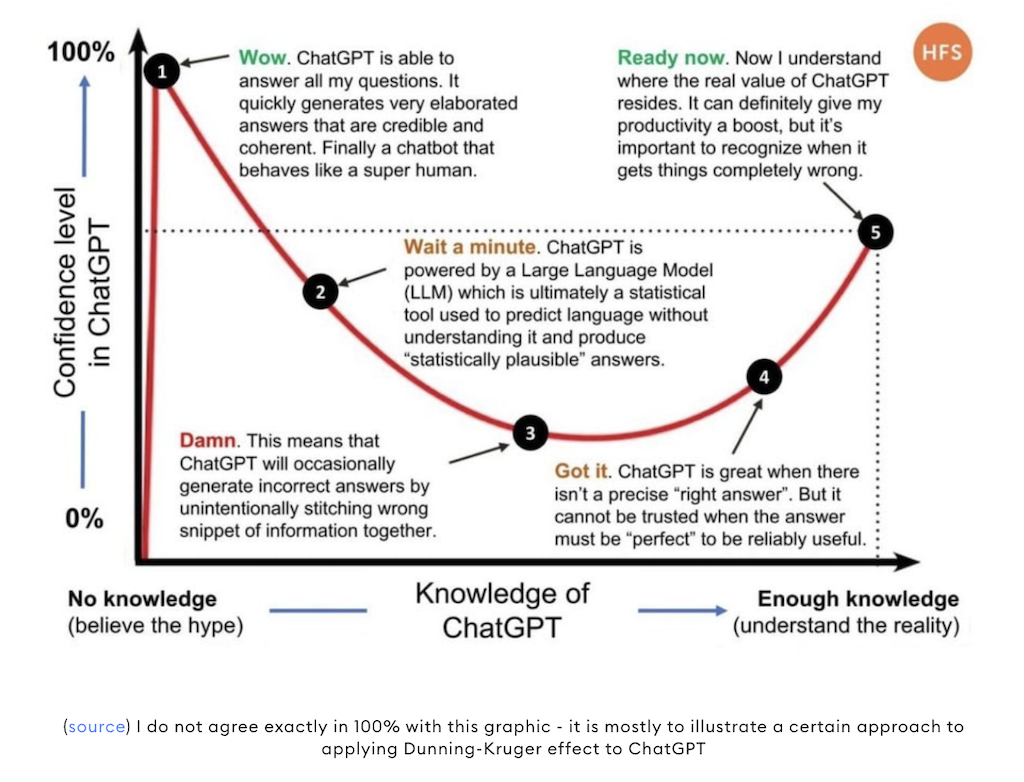
Tatsächlich ist es aktuell schwer, eine treffsichere Vorhersage zu fällen, weil die technischen Entwicklungen sich ständig überschlagen – von den politischen Entwicklungen und deren Auswirkungen auf die Techniklandschaft und Gesetzgebungen der Länder, in denen unsere Daten liegen, mal völlig abgesehen. Generell denke ich, dass wir gesellschaftlich gerade erst bei Phase 2 des abgebildeten Hype-Cycles sind und noch viel davon sehen werden. Denn gerade in großen Firmen dauern Entscheidungsprozesse mitunter Jahre und einige fangen jetzt erst an, sich damit zu beschäftigen.
Bei aller Begeisterung für die Technologie, sollten wir allerdings das Menschliche nicht aus den Augen verlieren. Und außerdem ein Auge auf die Kosten haben, die wir durch die Verwendung von KI-Systemen unweigerlich entweder selbst haben oder auch an anderer Stelle verursachen.
Ich persönlich denke, dass es auch in Zukunft Arbeit für Kreative geben wird. Und dass wir gut daran tun, unser ganz eigenes Menschsein mit allen Unperfektheiten hervorkehren sollten, wenn wir weiter als Kreative arbeiten wollen auf einem Markt, der mit generierten Inhalten geflutet wird.
Worüber reden wir eigentlich? Unsere Sprache für KI
So, wie wir von "KI" reden, suggerieren wir die ganze Zeit, dass wir es mit einem intelligenten Gegenüber zu tun haben. Insbesondere Wörter wie "der halluziniert", "die antwortet mit und löst meine Probleme" etc., sind ein Framing / Priming für unser Gehirn und wir stellen uns die ganze Zeit beim darüber Denken oder Reden selbst ein Bein. Denn unser Gehirn denkt somit in Kategorien, die Menschen und intelligenten Wesen vorbehalten sind. Wir haben aktuell noch keine Sprache, um mit einem maschinellen Gegenüber umgehen zu können.
Vieles von dem, was heute "KI" genannt wird, sind immernoch dieselben Algorithmen, die wir auch schon vor drei Jahren (oder noch viel länger) hatten. Gesichtserkennungsalgorithmen gibt es beispielsweise schon seit 2001. Nur, dass "KI" sich auf Vortragsfolien trendier macht und außerdem jetzt überall draufstehen muss, um Fördergelder zu bekommen. Wo vor zehn Jahren noch "Blockchain" stand, steht jetzt eben "KI". Ja, die Entwicklungen schreiten voran und in Teilen auch sehr schnell, aber das wenigste, mit dem wir es zu tun haben, ist tatsächlich intelligent. Das meiste sind schnöde Algorithmen, also sehr detaillierte Anweisungen, wie eine Software bestimmte Daten verwenden soll.
Algorithmen und auch sogenannte "KI" mit ihren sogenannten "neuronalen Netzwerken" sind jeweils ein Stück Software, das auf einem Stück Hardwäre läuft, dabei eine Menge Strom und Wasser verbraucht und CO₂ produziert. Dabei laufen diese neuronalen Netze, also die Software, die diese Simulation fährt, im Arbeitsspeicher der Grafikkarte, im allgemeinen Arbeitsspeicher des Rechners oder manche auch im Hauptprozessor, der CPU. Wenn man den Stecker rauszieht oder auch einfach das Programm beendet, ist alles davon wieder weg.
Cloud-Services
Viele der KI-Anwendungen werden als Cloud-Services betrieben. Meistens deswegen, weil unsere Laptops oder Telefone nicht einmal die Rechenleistung haben, die es braucht, um diese Systeme zu betreiben. Das bringt allerdings ein paar Probleme.
There is no cloud, just other people's computers.
FSFE.org
Die Free Software Foundation Europe (FSFE) hat es sehr treffend formuliert: Es gibt keine Cloud, nur die Rechner anderer Leute. Alles, was nicht auf euren Rechnern läuft, läuft eben auf den Rechnern anderer Leute und andere Leute haben auch entsprechend Zugriff auf und die Hoheit über eure Informationen.
Wem gehören die Daten?
Eine ganz große Frage, die sich daraus ergibt ist die nach der Rechtslage des Landes, wo die Firma, der man die eigenen Daten anvertraut hat, den Firmensitz hat. Denn durch den Firmensitz ist sie an die Rechtslage in dem Land gebunden (wäre ja schade, wenn deren Gewerbeschein was passieren würde ...).
- In Europa haben wir es als Menschen und datenverursachende Subjekte sehr gut, denn in Europa gehören die Daten uns.
- In den USA sieht es anders aus. Da gehören die Daten den Unternehmen.
- Und in China gehören die Daten dem Staat.
Während viele Fediverse-Server in Europa betrieben werden und damit datenschutzkonform nutzbar sind, liegen fast alle kommerziellen Social-Media-Plattformen und auch der Großteil der KI-Plattformen in den USA. Und DeepSeek und TikTok gehören zu staatsnahen chinesischen Unternehmen. (*Fußnote: Nahezu alles, was aus dem Silicon Valley kommt, kann man mittlerweile als staatsnahe Unternehmen in den USA bezeichnen.)
Google ist nicht unser Freund
Abgesehen davon, dass Google ein staatsnahes US-Unternehmen ist und außerdem ein Werbeanbieter mit angeschlossenen Services, die allesamt dazu dienen, Daten über Menschen einzusammeln, um ihnen Werbung verkaufen zu können (warum glaubt ihr, zahlt ihr kein Geld dafür, die Services nutzen zu dürfen?), hat Google auch eine hart aggressive KI-Strategie: "Google Says It’ll Scrape Everything You Post Online for AI" schrieb Gizmodo nach einer großen Änderung der Google AGB im Juli 2023, was die Inhalte der Änderung ziemlich gut zusammenfasst. Ihr könnt auch selbst mal in die Google AGB reinschauen und nachlesen. Besonders interessant ist der Teil in dem steht, welche Lizenzen ihr Google an euren Inhalten gebt und dass sie die auch an Dritte unterlizensieren dürfen.

All diese Daten laufen zum einen in Googles Werbemaschinerie hinein, zum anderen auch in das Training von Googles KI. Wenn ihr also Manuskripte in Google Docs schreibt oder per Gmail schickt, fließt alles davon in Googles KI. Wechselt am besten euren Mailanbieter zu Mailbox.org oder Posteo, beide in Deutschland und für €1,- pro Monat zu haben. Mehr dazu in der Blogpost-Serie zu Basic Internet Security (aktuell auf Englisch, Deutsch kommt bald) oder in meinem Buch "Dann haben die halt meine Daten. Na und?!".
Microsoft & Meta (Instagram, Facebook, Whatsapp, Oculus Rift ...)
Alles, was ihr mit Microsoft-Produkten wie Office365 macht, läuft in Microsofts KI und deren Training hinein. Microsoft läuft immer so schön unter dem Radar, hat aber mit Xandr einen sehr großen Daten-Marktplatz am Start, der durch alles, was wir mit Microsoft-Services tun, ebenfalls fleißig gefüttert wird. Ja, das gilt insbesondere für Windows und Office365. LibreOffice und Pages können das mit der Änderungsverfolgung übrigens auch und man braucht kein Word, um doc oder docx Dateien zu öffnen oder darin abzuspeichern. Und Office-Makros sollte man schon aus Sicherheitsgründen niemals verwenden und Dokumente mit Makros auch nicht annehmen – looking at you, Verlage!
Alles, was ihr mit Instagram oder Facebook macht, läuft entsprechend an Meta und das Training von deren KI. Eure Gesprächs-Profile von WhatsApp natürlich ebenfalls. Und die Lizenz, eure Social-Media-Inhalte kommerziell zu verwenden, zu verkaufen und unterzulizenzieren habt ihr ihnen durch die Verwendung der Plattform bereits erteilt.
Falls ihr euch fragt, wann genau ihr dem zugestimmt habt: Das war das kleine Häkchen, damit der Weiter-Button bei der Registrierung geht.
Amazons Daten-Pool und ihr KI-Training
Natürlich hat auch Amazon nicht nur einen riesigen Daten-Pool mit sämtlichen Büchern, die je über Amazon verkauft wurden und alles, was sie aus unserem Surf- und Einkaufsverhalten herausziehen, sondern auch eine KI, die sie höchstwahrscheinlich mit all diesen Daten füttern.
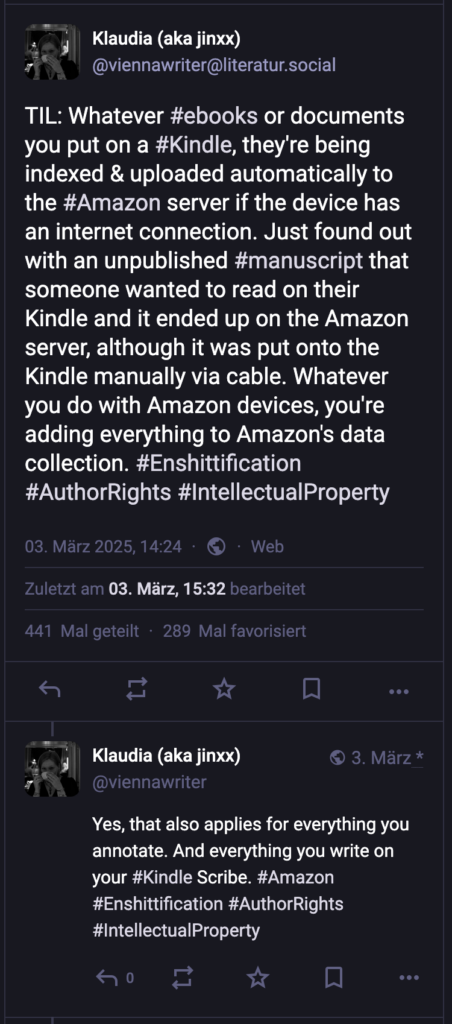
Unlängst haben wir herausgefunden, dass Amazon sämtliche Dokumente, die man – auch via Kabel direkt – auf ein Kindle-Gerät lädt, auf den Amazon-Servern landen, wenn das Gerät irgendwie mit dem Internet kommunizieren kann. Das gilt auch für unveröffentlichte Manuskripte, die Testlesende auf ihren Kindle-Geräten anzeigen lassen. Sobald das Gerät irgendwie Netzverbindung hat, spiegelt es alles auf die Amazon-Server. Es gibt Kindle-Geräte, die brauchen dazu nichtmal WLAN, sondern verbinden sich immer direkt per eingebauter SIM-Karte selbst mit dem Netz.
Von den Notizen und Anmerkungen, die wir in Büchern und Dokumenten auf Kindle-Geräten machen können, wussten wir das ja schon. Und nachdem Kindle-Scribe-Geräte grundsätzlich durch Amazons Server synchronisieren, war das für diese auch von Beginn an klar. Dass das aber auch Bücher und Dokumente betrifft, die man nicht via Amazon Services wie "An Kindle senden" und diese praktische Kindle-Mailadresse gilt, war tatsächlich durchaus schockierend – auch für die Autor:innen, die den Fund bei sich überprüft haben und bestätigen konnten.
Wenn die Dokumente und Manuskripte jetzt in Amazons KI gewandert sind, kann man das nicht mehr ändern, denn raus kriegt man sie aus so einem KI-Datenpool nicht mehr. Das heißt aber nicht, dass man deswegen jetzt resignieren kann, sondern: jetzt erst recht! Alles, was irgendwie möglich ist: Löschen. Ggf. vorher Screenshots machen, um noch Beweismaterial zu haben, wenn wir es bis zu einer Sammelklage schaffen.
Grundsätzlich gilt: Wir tun alle gut daran, aus dem geschlossenen Amazon-Garten hinaus zu kommen. Sowohl für unsere Lesenden als auch für uns selbst und unser geistiges Eigentum.
Piraterie und unsere Bücher als Trainingsdaten

Apropos geistiges und Daten-Eigentum: LibGen, Anna’s Archive, Pirate Bay und unsere Bücher sind auch wieder eine lange Geschichte. Seit Jahren kämpfen Autor:innen-Verbände gegen Piraterie-Plattformen. Andere laden ihre eigenen Werke direkt selbst auf diese Plattformen hoch und erreichen damit Rekordumsätze. Und wieder andere wie Cory Doctorow oder Uwe Lübbermann arbeiten einfach gleich nach Creative Commons Grundsätzen. Wir werden diese Grundsatzdiskussion hier nicht lösen. Aber wir können uns darauf einigen, dass ungefragt piratisierte Werke als KI-Trainingsdaten zu verwenden echt uncool ist.
Im März 2025 hat The Atlantic eine große Recherche veröffentlicht: The Unbelievable Scale of AI’s Pirated-Books Problem. Dazu auch eine Seite, auf der man LibGen durchsuchen kann, ob und wenn ja welche der eigenen Bücher in der Piraterie-Datenbank stecken und somit in die Trainingsdaten von Metas KI geflossen sind.
Von mir haben sie zumindest auch das Datenschutz-Sachbuch "Dann haben die halt meine Daten. Na und?!" genommen – was ja auch irgendwie passend und beruhigend ist.
KI-generierte Inhalte und das Urheberrecht
Das ist jetzt unfair, aber während unsere urheberrechtlich geschützten Inhalte als Trainingsdaten oder durch unsere Interaktion mit den Modellen direkt in die verschiedenen Modelle reinfließen und somit ins Daten-Konglomerat der Hersteller eingehen, haben wir umgekehrt kein Urheberrecht an den generierten Inhalten. In den USA ist das bereits rechtlich so entschieden. Dort hat Anfang 2023 erst das Copyright Office einen Antrag auf Eintrag eines KI-generierten "Kunstwerks" abgelehnt. Dagegen klagte der Antragsteller und das Gericht bestätigte im August 2023 die Entscheidung des Copyright Office mit der Begründung: „Urheberschaft durch einen Menschen ist wesentlicher Bestandteil eines gültigen Urheberrechtsanspruchs.“
In Europa können wir alle möglichen Rechte an unseren Werken abgeben oder lizenzieren, das Urheberrecht haben wir hier aber immer automatisch an unseren von uns selbst durch unsere kreative Leistung geschaffenen Werke, ohne dass wir diese erst eintragen lassen müssen. Dennoch geht es auch bei unserem Urheberrecht hier immer um die Urheberschaft durch einen Menschen. Somit ist die Entscheidung aus den USA richtungsweisend und ich erwarte, dass wir bald eine ähnliche Regelung im deutschsprachigen Raum bekommen werden.
Large Language Models (LLM)
Als ChatGPT im November 2022 auf das Internet losgelassen wurde, wuchs die Nutzendenbasis binnen kürzester Zeit rasant an. Es ist ja auch wirklich spannend zu beobachten und nett, damit herumzuspielen. Neben ChatGPT (OpenAI) gibt es auch noch claude.ai (Anthropic), Grok (Twitter/X), Copilot (Microsoft), Gemini (Google), Llama (Meta), LeChat (Mistral), DeepSeek (das chinesische Modell) und Plattformen wie Poe oder duck.ai, wo man mehrere dieser Modelle zur Verfügung hat, die eine davon zumindest etwas datenschutzfreundlicher (duck.ai) als die andere (Poe). Mein eigenes urheberrechtlich geschütztes Material würde ich persönlich bei keiner der Plattformen hochladen. Aber das ist meine ganz eigene Entscheidung und Autor:innen wie zB Joanna Penn sehen das anders und nutzen all diese Tools mit ihrem eigenen intellectual property (IP) sehr freigiebig.
Ich persönlich würde für die Verarbeitung meines eigenen geistigen Eigentums wenn dann ein lokales Modell verwenden, das ich auf meinem eigenen Rechner laufen lasse. Wenn es soweit ist, mache ich dazu nochmal einen eigenen Blogpost. Von den lokalen Modellen gibt es auch einige, aus denen man aussuchen kann, viele davon liegen gratis und Open-Source vor, allerdings sind diese dann bedeutend kleiner, weil unsere Heimcomputer allesamt nicht soviel "Platz" im Arbeitsspeicher oder dem Grafikkartenspeicher haben, wie die großen Modelle es verlangen. Hier gilt es dann, kleine Brötchen zu backen und ein Modell zu finden, das klein genug für den eigenen Rechner ist und das trotzdem schon genug kann, um den eigenen Anwendungsfall zumindest zufriedenstellend abzudecken. Oder halt einen neuen Rechner kaufen oder Server mieten, der den Anforderungen entspricht.
Aber zurück zum Kern: Was machen diese Sprachmodelle eigentlich?
Kurz: Wahrscheinlichkeitsrechnung. Was ist statistisch der wahrscheinlich nächste Buchstabe und was ist das wahrscheinlich nächste Wort? Genau genommen ist es Matritzenrechnung und wer mag, kann das im Detail bei Wolfram Alpha nachlesen. Und damit das Modell nicht mit seiner Wahrscheinlichkeitsrechnung in eine Dauerschleife gerät, hat es zusätzlich einen Zufallsfaktor. Das ist der Regler an dem man dreht, wenn man ein Modell "kreativer" antworten lässt.
Es gibt eine schweizer Plattform namens Soekia, auf der man visuell dargestellt bekommt, wie ein LLM arbeitet, wie welche Quellen verwendet werden und die Ergebnisse zustande kommen.
Professor Emily Bender nennt LLMs "stochastische Papageien", weil sie nur aus einem gegebenen Set an Trainingsdaten "nachplappern" können, was da schon drin ist. Und "stochastisch" wegen der Wahrscheinlichkeitsrechnung.
Und was ist das Wahrscheinlichste?
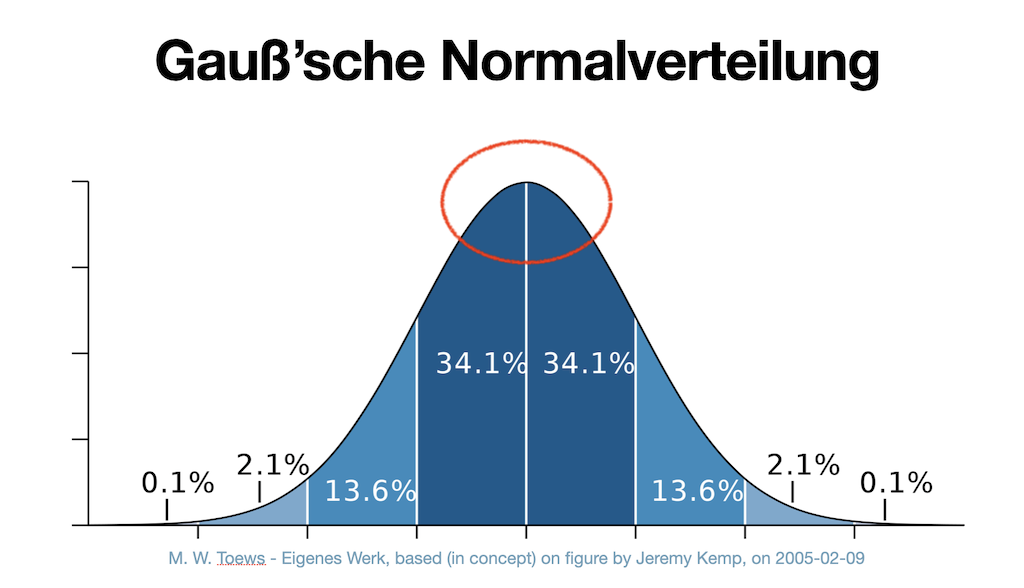
Das Wahrscheinlichste ist der obere Zipfel in dieser Normalverteilungskurve, da wo sich die 34,1% und 34,1% treffen. Die Spitze des Eisbergs. Sprich: Wir kriegen aus Sprachmodellen – wortwörtlich – maximal mittelmäßige Texte oder auch Bilder heraus. Die durchschnittliche Kaffeetasse – oder was auch immer euer Objekt der Wahl ist.
Das kann im Fall von Texten für Nicht-Muttersprachler:innen und Menschen, die sich in einen Themebereich einarbeiten, hilfreich sein. Aber für alle, die auch nur ein bisschen über das Mittelmaß hinaus Texte fabrizieren können (ich unterstelle: das sind alle Lesenden dieses Blogs), ist eine "Textverbesserung" per LLM ein Rückschritt. Es geht Kreativität und Varianz verloren. Dazu kommen wir bei den Übersetzungen gleich nochmal.
Es gibt eine Studie zu Design-Patterns, die auch Informationen darüber hat, warum wir als Menschen KI-Chatbots wie ChatGPT so faszinierend finden. Es lohnt sich, da mal reinzuschauen. Sehr kurz gefasst liegt es daran, dass un ein Gefühl von Befriedigung ereilt, wenn wir mit minimalem Aufwand (Prompt) ein maximales Ergebnis bekommen.
KI als Autor:in und/oder Kreative:r sinnvoll einsetzen
Ich sage nicht, dass ihr KI-Tools nicht verwenden sollt, sondern dass ihr euch der Rattenschwänze bewusst sein sollt, wenn ihr KI-Anwendungen benutzt. Ein paar Sachen sind aufgrund rechtlicher Rattenschwänze wenig sinnvoll, andere deswegen nicht, weil sie uns als Menschen, die mit Sprache arbeiten, nicht hilfreich sein werden und sogar einen Rückschritt bzw. einen Qualitätsverlust unserer Texte bedeuten. Aber andere Dinge sind bereits sehr gut und hilfreich, wie z.B. Speech-to-Text Anwendungen wie OpenWhisper (siehe unten), die man auf dem eigenen Gerät laufen lassen kann, beispielsweise um mündlich geführte Interviews automatisch zu transkribieren, ohne dass dabei die Inhalte an irgendeinen US-Service gegeben werden.
Von einer lieben Autorenkollegin hörte ich gerade, dass die Verlage mittlerweile ihre Verträge angepasst hätten und von den Autor:innen eine Bestätigung erwarten, dass sie keine KI für das Schreiben der Texte verwendet haben. Umgekehrt verpflichten sich die Verlage, dass sie die Manuskripte und Bücher nicht an KI "verfüttern", also keine Auswertung des Manuskripts, keine automatisch generierten Hörbücher, etc. Das finde ich grundsätzlich gut, das rechtlich zu klären, was erlaubt ist und was nicht und im Zweifelsfall reinzuschreiben, dass die Autor:in zustimmen muss, wenn irgendwas gemacht werden soll.
Ethische Überlegungen
Im englischsprachigen Bereich hat es sich durchgesetzt, keine Namen von Künstler:innen oder Autor:innen in Prompts zu nennen. Schon aus Respekt vor dem:der Kolleg:in, aber auch, um deren Stil nicht stur kopieren zu lassen. Das wird auch von Alli in UK, der Alliance of Independent Authors (Freundschafts-Link) immer wieder so proklamiert. Ich bin Mitglied dort und halte es persönlich für eine gute Sache, global respektvoll miteinander umzugehen.
Stattdessen umschreibt man den Stil, zB "Schreib diese Szene um im Stil, wie er in Amerika in bestselling Horror-Geschichten aktuell üblich ist". Ihr seid ja alle kreativ und werdet dafür Lösungen finden.
Mit verschiedenen Modellen reden
Eine Workshopteilnehmerin sagte, sie nutzt ChatGPT, weil sie mit dem Modell reden kann, also diktieren statt tippen. Auf die Idee wäre ich nicht gekommen, schon allein, um meine biometrischen Daten (Stimme) nicht an OpenAI zu geben, aber gut. Es gibt für alles Anwendungsfälle. Jedenfalls kann man auch mit Perplexity und anderen Modellen reden und ist allein deswegen nicht an ChatGPT gebunden.
Aktualität der Trainingsdaten ermitteln
Egal, was ihr vorhabt, es ist sinnvoll herauszufinden, wie aktuell die Informationen sein können, die aus einem KI-Modell herauskommen können. Dazu kann man eine einfache Frage stellen:
Prompt:
Bis zu welchem Zeitpunkt reichen deine Trainingsdaten?
Kontext ist wichtig
Es ergibt Sinn, für jedes Thema einen neuen Thread zu eröffnen und nicht im selben Thread Fragen zu völlig unterschiedlichen Themen zu stellen.
Je nach Modell und Plattform könnt ihr "Threads" oder "Räume" aufmachen, um in bestimmten Kontexten zu bleiben. Bei der Vielzahl an Plattformen schaut einfach, was euer ausgesuchtes Modell euch anbietet. Fragt es ggf auch einfach, wie ihr mit ihm interagieren sollt, um euer Ziel zu erreichen.
Pro-Accounts
Wenn man wirklich mit den Modellen arbeiten möchte, lohnt sich fast immer ein Pro-Account. Die müssen auch nicht gleich für das ganze Jahr bezahlt werden, sondern man kann konkret für den Monat, in dem man die Recherche macht oder an dem Plot arbeitet, gezielt das Pro-Abo abschließen und dann wieder kündigen.
Suchen & Recherche
Egal, was sich so eingeschliffen hat, ChatGPT ist KEINE Suchmaschine! Ja, mit der Weltkugel beim Eingabefeld kann man die Software anweisen, auch aktuellere Onlinequellen hinzuzuziehen, dennoch ist die Wahrscheinlichkeit, dass Falschangaben ausgegeben werden, sehr hoch. Egal ob New Yorker Anwalt, der von ChatGPT "erfundene" Referenzfälle vor Gericht vorträgt und dann fast seine Anwaltslizenz verliert, oder Googles KI, die ausgibt, man solle pro Tag einen kleinen Stein essen oder Klebstoff in Pizzakäse mischen, damit der nicht von der Pizza fließt, das sind Ausgaben von LLMs, die mitunter schwere Folgen für die Karriere oder die Gesundheit haben. Vom Suchen per ChatGPT oder anderen LLMs nach Krankheitssymptomen etc ist überhaupt stark abzuraten. Tut es einfach nicht. Dafür sind die Modelle nicht gebaut.
Perplexity
Für KI-gestützte Suchanfragen nutzt gerne Perplexity. Das Modell ist als Suchmaschine gebaut und man bekommt die tatsächlichen Quellen angezeigt und kann nachvollziehen, woher die Antworten gekommen sind.
Ich bin tatsächlich ein großer Fan von Perplexity und finde die generierten Antworten zumeist sehr gut. Man kann die Ergebnisse durch die Modellauswahl natürlich weiter beeinflusen und gerade bei den Reasoning-Modellen können die Unterschiede wirklich groß sein. Alleine dafür lohnt es sich, den Pro-Account auszuprobieren.
Grundsätzlich gilt: Eine KI-gestützte Suche ist hilfreich für den Einstieg in eine Recherche – in etwa wie ein Wikipedia-Artikel, der auch eine erste Anlaufstelle sein kann, ehe man sich dann durch die Primär- und Sekundärquellen unter dem Artikel arbeitet und weiter in das Thema einsteigt. Es ist eine Abkürzung zu einer kleineren Menge an Quellen und kann einem eine Richtung zeigen, in der man dann weiter recherchiert. Es ist aber nichts im Vergleich dazu, sich die Zeit zu nehmen, und die Informationen selbst zu erarbeiten, sich das Wissen selbst anzueignen, zu verinnerlichen ("im Gehirn zu installieren"). Wenn ihr nen Sixpack wollt, reicht es ja auch nicht, euer Telefon ins Fitnessstudio zu schicken.
Tiefenrecherche mit Perplexity
Perplexity bietet auch die Möglichkeit, eine Tiefenrecherche anzustellen, dazu klickt man unter dem Eingabefeld statt Search (deutsch: Suche) auf Research (deutsch: Forschung). Es dauert dann eine Weile, aber die Tiefenrecherche ist schon sehr beeindruckend. Dabei geht das Modell die Frage(n) durch, die Anzeige ändert sich immer mal, je nachdem an welcher Stelle der Fragestellung und Quellensuche es gerade ist. Gegenüber der normalen KI-gestützten Suche analysiert Perplexity bei einer Tiefenrecherche mehr Quellen (falls vorhanden).
Je nach Fragestellung und Themengebiet kann die Tiefenrecherche durchaus länger dauern (bis zu 30min), aber dabei schon sehr hilfreich sein, um sich in Themengebiete einzuarbeiten. Alleine darauf verlassen würde ich mich allerdings auch hier nicht. Für einen Einstieg sind die Ergebnisse durchaus verwendbar. Ich habe bei einigen Suchanfragen allerdings auch hier schon die Grenzen gefunden, wenn es einfach keine oder widersprüchliche Zahlen zu etwas gibt (siehe weiter unten).
Die Funktion ist auch ohne Pro-Account verfügbar, hat dann allerdings ein Tageslimit. Da will der Prompt schon gut überlegt sein.
Made o'Meter
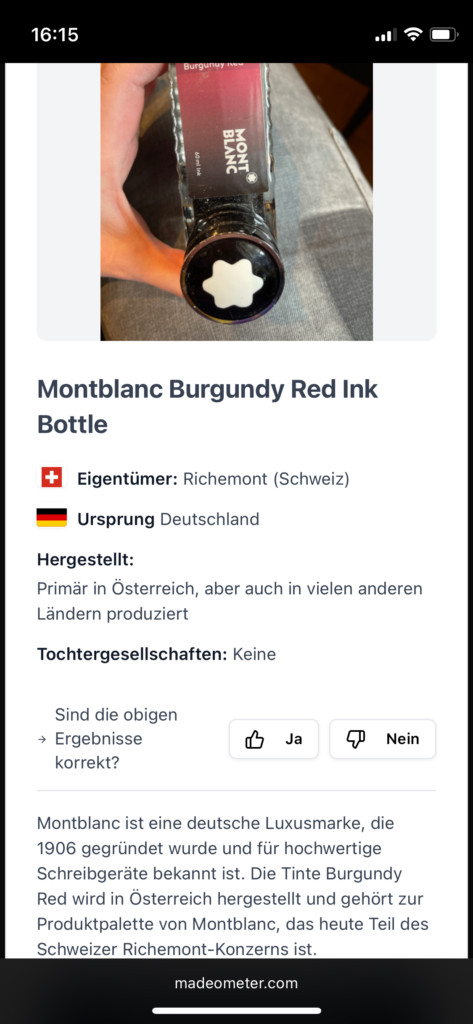
Nicht direkt schreib-bezogen, aber durchaus interessant und vielleicht auch für eine Recherche gut: Made O'Meter.
Ein paar dänische Menschen hatten eine gute Idee in der aktuell angespannten Situation im Handelskrieg mit den USA: Buy European. Dazu haben sie eine KI-gestützte Suchmaschine namens "Made O'Meter" gebaut, zu der man ein Foto eines Produkts / einer Verpackung hochladen kann und das Ding gibt einem dann aus, wer der Hersteller des Produkts ist, wo dessen Firmensitz ist und wo es produziert wird. Das Modell ging Anfang März 2025 in Betrieb und war vier Tage später schon wieder offline, weil es Falschinformationen ausgab. Dann wurde es bis Mitte April 2025 überarbeitet und ist jetzt wieder unter https://madeometer.com/ erreichbar.
KI-Suche Don't
- ChatGPT, Grok, Gemini, oder sonst ein reines LLM für Suche verwenden
- Für wahr halten, was von einem LLM ausgegeben wird
- Daten von Menschen eingeben
KI-Suche Do
- Ausgaben überprüfen
KI-Suche Trade-off
- Es verleitet dazu, überall und nur noch die Abkürzung zu nehmen
- KI-gestützte Suche verbraucht 10x soviel Strom wie eine datenbankbasierte Abfrage
- Reasoning-Modelle verbrauchen noch mehr Strom und Wasser als die KI-gestützte Suche
Textgenerierung / -bearbeitung
Mit ChatGPT fing alles an, aber auch wenn dieser Markenname in aller Munde ist, ist das Modell vom US-Hersteller OpenAI nicht das einzige auf dem Markt. Es gibt noch eine Reihe weiterer wie Claude von Anthropic (USA), LeChat von Mistral (Frankreich), Llama von Meta (USA), ...
Mit DeepSeek ist auch ein chinesisches Modell auf dem Markt, das zwar technologisch interessant zu sein scheint, da es angeblich viel weniger Ressourcen verbraucht als alle anderen vergleichbaren Modelle, allerdings mit dem sehr großen Tradeoff, dass dann alle eingegebenen Daten direkt an ein staatsnahes chinesisches Unternehmen fließen, das mit denen dann macht, was es will.
Googles KI namens Gemini (vormals Bard genannt, USA) und Grok von Twitter/X (USA) lasse ich absichtlich in der Betrachtung aus. Erstere weil Google für Autor:innen grundsätzlich schwierig ist (s.o.) – da habe ich nur etwas später noch ein Beispiel für Euch, was wirklich auffallend ist. Und über Ex-Twitter müssen wir nicht reden. Wenn jemand ethisch fragwürdige Modelle besichtigen möchte, kann die Person das dort gerne tun.
Grundsätzlich gehe ich davon aus, dass Autor:innen, die diesen Blogpost lesen, nicht auf die Idee kommen, ihre Bücher per ChatGPT verfassen zu lassen. Falls doch, lasst es mich kurz sagen: Einfach nein. Es ist keine gute Idee, ganze Romane per ChatGPT oder sonst einem LLM einfach erstellen zu lassen. Das wäre ein Produkt, bei dem die kreative Leistung im einstelligen Prozentbereich liegt und obendrein ethisch äußerst fragwürdig.
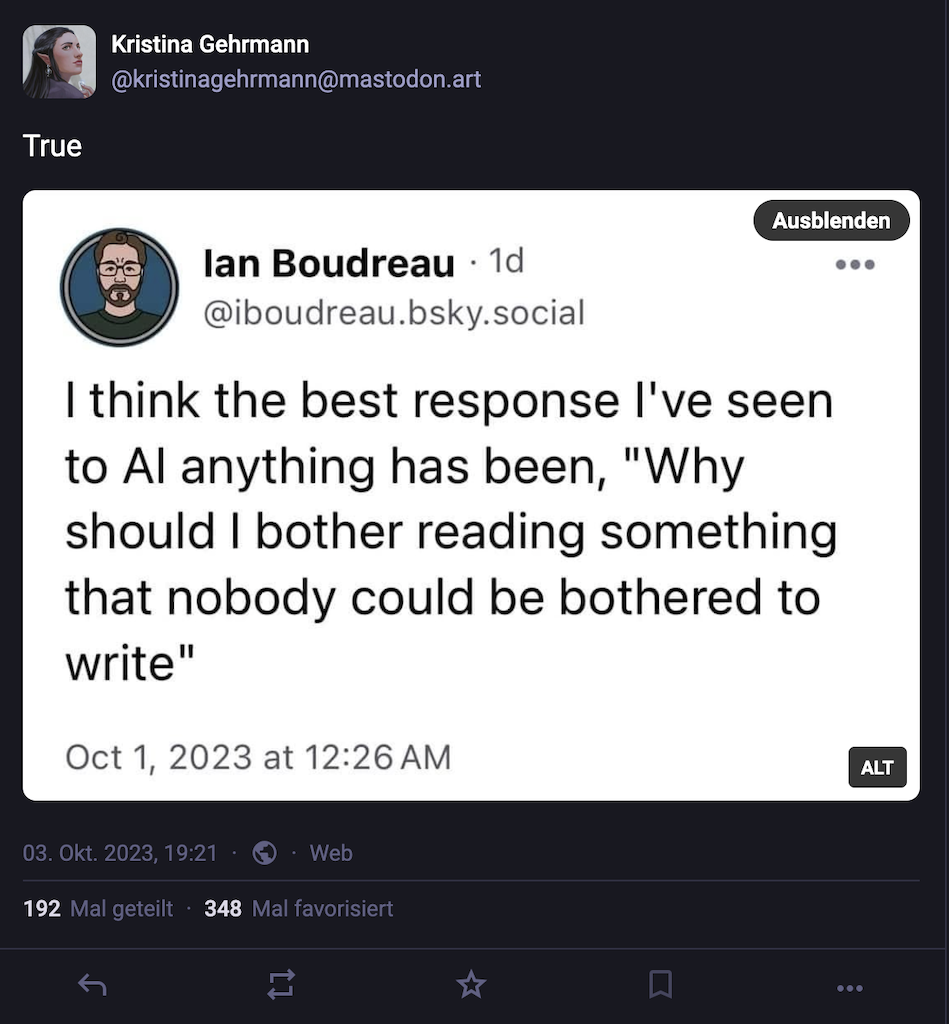
Eine Antwort, die ich noch immer extrem passend finde, was mit einer generativen KI erstellten Texte angeht, ist diese hier: Why should I bother reading something that nobody could be bothered to write?
Das Zitat zeige ich auch den Studis immer und sage ihnen, dass ich kein Problem damit habe, wenn sie sich von einem Large Langugae Model (LLM) wie ChatGPT oder Claude helfen lassen, falls ihr Problem das sprichwörtliche weiße Blatt Papier ist, damit sie schonmal einen Rahmen haben. Ich will aber lesen und am Text sehen, dass sie selbst nachgedacht und ihre eigenen Inhalte eingefügt haben.
Grundsätzlich gibt es aber durchaus ein paar kreative Arbeiten, die man mit ChatGPT und anderen LLMs durchaus lösen kann.
Modelle ausprobieren mit duck.ai
Unter duck.ai könnt ihr verschieden Modelle wie GPT 4o mini, Mistral, Claude etc. gratis und zummindest ein bisschen datenschutzfreundlicher und recht einfach ausprobieren, um die Unterschiede zwischen den Modellen herauszufinden und welches davon besser zu eurem aktuellen Anwendungsfall passt. Aber auch hier gilt: keine personenbezogenen Daten hochladen, ethisch fair prompten etc.
Achtung: Die Modelle werden laufend weiterentwickelt und neue Versionen veröffentlicht. Schaut ggf in drei oder sechs Monaten, was sich geändert hat und ob dann eventuell ein anderes besser zu eurem Anwendungsfall passt.
Besser prompten mit der R-Z-K(-A)-Regel
Um in bestimmten Kontexten mit dem Modell zu interagieren, gebt ihm eine Rolle, aus der heraus es Antworten generieren soll. Wenn beispielsweise euer Problem ist, dass eure Heizung kaputt ist, könntet ihr dem Modell die Aufgabe geben, als Expert:in für energetische Sanierung mit euch zu kommunizieren und eure Fragen aus diesem Blickwinkel zu beantworten.
- Rolle
- Ziel
- Kontext
- Ausgabeformat
Prompt:
Du bist Expertin für energetische Sanierung. Unsere 23 Jahre alte Gasheizung ist kaputt und muss getauscht werden. Wir leben in einem freistehenden Haus aus den 1970ern in einem Dorf in [Bundesland]. Welche Heizungen wären für unser Haus möglich? Und welche Fördermöglichkeiten gibt es dieses Jahr, um zukunftssicher eine neue Heizung für unser Haus anzuschaffen?
Ein Beispiel mit gesetztem Ausgabeformat hatten wir neulich in einem Workshop mit Lehrlingen:
Prompt:
Du bist Zahnarzt und sollst mir dabei helfen, eine gute Routine in der Zahnpflege zu entwickeln. Ich habe eine Brücke. Erstelle mir einen Tagesplan mit geeigneten Maßnahmen in tabellarischer Form.
Grundsätzlich könnt ihr diese Technik auch auf der Meta-Ebene anwenden und das Modell zB eure Prompts verbessern lassen:
Prompt:
Du bist Experte für Prompt-Engineering und sollst mir dabei helfen, einen perfekten Prompt für folgendes Problem zu finden: (Problemstellung)
Interview mit eurer Hauptfigur
Eine Sache, wofür man ChatGPT & Co tatsächlich sinnvoll verwenden kann ist ein Interview mit beispielsweise eurer Hauptfigur, um diese und ihr Leben, ihre täglichen Probleme besser kennenzulernen. Die R-Z-K-A-Regel hilft euch auch hier dabei.
Prompt:
Du bist ein 52-jähriger Corn-Farmer aus [US-Bundesstaat]. Deine Famile ist [Infos zur Familie, Namen, Alter ...]. Dein Ziel ist [Ziel der Figur]. Beantworte mir alle folgenden Fragen aus dieser Perspektive.
Texte verbessern und umformulieren
Viele Jugendliche und Studis verwenden ChatGPT zum Umformulieren von Texten, damit die "professioneller" klingen. Mit Blick auf die Gauß'sche Normalverteilung und die Wahrscheinlichkeit, dass Texte dadurch wirklich "besser" werden, ist es eine gewagte Annahme, dass die Texte am Ende wirklich besser wären. Einige sagten, dass sie Mails von ChatGPT generieren lassen, damit das korrekte Fachvokabular drin ist. So weit, so okay-ish, wenn sie auf meine Folgefrage, ob sie die Mails denn in einem Jahr selbst schreiben würden, wenn sie das Fachvokabular dann kennen, nicht geantwortet hätten: "Nein, warum denn?"
Anmerkung: Es ist eine ganz, ganz schlechte Idee, ganze Mailverläufe mit sämtlichen personenbezogenen Daten, Firmengeheimnissen und -interna, Produktneuentwicklungen etc. in ein Sprachmodell zu laden, um sich die fünf Minuten zu sparen, selbst eine Antwort zu tippen! Wer das tut, hat den Jackpot und damit ein Gespräch mit dem Datenschutz-Beauftragten und der IT-Security-Beauftragten der Firma gewonnen. Im Zweifelsfall läuft das auf eine Selbstanzeige der Firma bei der zuständigen Datenschutzbehörde raus. Oder es ist der Verlust der kompletten Produktneuentwicklung, wenn der Code eines Softwareprodukts direkt an die Herstellerfirma des verwendeten Modells verschenkt wurde. (Abgesehen davon ist mit KI entwicketler Code unsicherer als der von Menschen geschriebene.)
Dabei wäre alles so einfach. Man kann auch DeepL Write verwenden. DeepL kennt man als Übersetzungstool (siehe unten), aber DeepL Write kann helfen, Texte zu verbessern und umzuschreiben.
DeepL Write ist DSGVO-konform und für Firmen bzw. berufliche Nutzung bekommt man auch einen Auftragsverarbeitungsvertrag (AVV) nach DSGVO. Im Gegensatz zu ChatGPT hat DeepL den Firmensitz in Köln, ist also an deutsches und Europa-Recht gebunden und bietet sehr gute Datenschutz-Features.
Die Pro-Variante von DeepL Write ist mit € 15,- pro Monat (€ 10,- bei jährlicher Zahlung) durchaus leistbar, insbesondere im beruflichen Kontext.
Textverbesserung auf Englisch mit ProWritingAid
Ich bin ein großer Fan von ProWritingAid (deswegen ist das auch ein Affiliate-Link mit 20% Rabatt für euch).
Was andere für Deutsch mit ChatGPT machen, kann ich als Nicht-Muttersprachlerin in Englisch absolut verstehen. Ich schreibe viele Texte auf Englisch und nutze ProWritingAid dazu, diese soweit zu überarbeiten, dass eine professionelle Lektorin dann gut damit arbeiten kann, und den Text zum Glänzen bringt, weil sie sich nicht mehr mit fehlenden (oder zu vielen) Kommas und sonstigen Kleinigkeiten aufhalten muss. Die Umformulierungs-Vorschläge nutze ich persönlich allerdings so gut wie nie, weil mir die oft zu "global blutleer" sind.
Ich habe bei ProWritingAid tatsächlich eine Lifetime Premium License, weil ich es mehrfach die Woche nutze und es sich für mich wirklich auszahlt. Es gäbe auch noch Premium Pro, aber man muss ja auch nicht übertreiben. Die Basisvariante ist gratis und man kann es sich auch – wie die meisten anderen Sachen – mal für $ 10,- einen Monat lang anschauen, ob man die Pro-Features haben möchte.
Man kann ProWritingAid im Browser verwenden oder das Programm herunterladen und lokal installieren. Das ist sehr praktisch, weil man da auch die Dateien aus Scrivener drin öffnen kann (wenn sie in Scrivener geschlossen sind) und dann direkt in der Manuskript-Datei arbeitet. Es öffnet natürlich auch alle möglichen anderen Arten von Textdateien.
Allerdings braucht es auch immer eine Verbindung zum Internet – was auf langen Zugfahrten durch Deutschland schade ist.
Plotten und Geschichten generieren mit Sudowrite
Sudowrite ist eine englischsprachige "Story-Engine", in die man alle Bestandteile einer Geschichte einfüllt, also alles, was man schon an Ideen hat. Man kann Charaktere erstellen und ein Genre auswählen und sich dann Vorschläge für Handlungsorte generieren lassen. Oder umgekehrt. Das Modell generiert aus den gegebenen Teilen passende weitere Teile wie zB eine Outline. Letztlich kann man das gesamte Buch dann auf der Plattform schreiben bzw im Wechsel auch generieren lassen. Ob das eine gute Idee ist das zu tun, sei dahingestellt.
Ich habe es ein paarmal mit Schulklassen bzw. den Kindern bei der Jungen Uni verwendet und sie haben selbst herausgefunden, wie formelhaft die Geschichten daraus werden und wie platt die Übersetzungen zwischen verschiedenen Sprachen, wenn wir sprachlich gemischte Gruppen waren. Dann haben wir die generierten Teile per DeepL in andere Sprachen übersetzt und zurück zu Englisch, um mit Sudowrite weiterzuarbeiten.
In die gleiche Kerbe wie Sudowrite schlägt auch Fictionary, womit ich aber noch keine Erfahrungswerte habe.
Instant Blurb
Klappentexte schreiben ist eine Kunst – zu Recht. Oder man macht es sich einfach und lässt die KI schreiben. Das kann man ChatGPT machen lassen oder spezialisierte Services wie Damonzas Instanz Blurb damit betrauen.
Achtung: Wenn ihr eure gesamten Bücher hochladet, um der KI Futter für den Klappentext zu geben, dann gebt ihr euer urheberrechtlich geschütztes Werk als gratis KI-Trainingsmaterial an den Hersteller der jeweiligen Plattform.
Ich habe beides noch nicht aktiv mit echten Büchern ausprobiert, da ich meine Werke nicht einfach irgendwo hochladen will. Wenn, dann würde ich nur eine grobe Beschreibung der Handlung mit fake Namen eingeben und das Ergebnis entsprechend anpassen. Oder ich bleibe einfach dabei und frage die Lektorin und die Testlesenden, was sie besonders an dem Buch mochten und nutze ihre Aussagen dafür, die Verkaufstexte zu formulieren, wobei sich das auch kombinieren ließe.
KI-Textgenerierung Don't
- Namen von Autor:innen/Künstler:innen in den Prompts nennen
- Informationen in generierten Texten für wahr halten
- Daten von Menschen eingeben
- KI-generierte Teile in eigenen Texten verschweigen
KI-Textgenerierung Do
- Ethisch verantwortungsvoll prompten (keine (Künstler-)Namen nennen, gewünschten Stil umschreiben etc.)
- Gewünschten Output beschreiben (Textlänge, Stil, Tabellenform ...)
- Verlagsvertrag nochmal lesen, was der Verlag zB zur Kennzeichnung von KI-generierten Inhalten im Text erwartet
- Verwendete generierte Text-Teile in euren Texten/Büchern/Blogposts auf jeden Fall ausweisen
- Ausgaben immer überprüfen
KI-Textgenerierung Trade-Off
- Alles, was ihr bei kommerziellen Modellen eingebt, wird zu Trainingsdaten (inklusive eurer Stimmdaten, falls ihr diktiert) und kann ggf auch in Teilen oder in der Essenz der Aussage anderen Leuten in ihrer Antwort serviert werden
- Modelle selbst betreiben ist häufig (noch) nicht einfach oder günstig möglich
- Wasser- & Stromverbrauch, wenn man ChatGPT eine kurze E-Mail verfassen lässt: ein halber Liter Wasser und genügend Energie, um 14 LED-Lampen für eine Stunde zu betreiben
KI-gestützte Übersetzungen
Früher hieß es schon "Nimm DeepL, das ist besser als Google Translate" und das stimmt auch noch heute. DeepL ist so ziemlich der "Gold-Standard", was Übersetzungsprogramme angeht. Jetzt haben sie es auch "KI" genannt, unter der Haube ist es aber noch immer das algorithmenbasierte Übersetzungstool von vorher, das auch ohne den KI-Hype weiterentwickelt worden wäre. Jetzt steht eben "KI" dran (siehen oben).
Die Ergebnisse von DeepL können sich wirklich sehen lassen. Allerdings sind auch sie nichts, was man einfach so unbearbeitet veröffentlichen könnte oder sollte, nicht einmal bei Sachtexten und bei literarischen Texten verursachen die Übersetzungen auch mit DeepL immer wieder noch ziemliche Bauchschmerzen. Denn auch DeepL baut alle paar Sätze Fehler ein und verdreht ab und an Dinge so, dass es genau das Gegenteil von dem aussagt, was im Text eigentlich steht. Von elegantem Satzbau oder Sprachgefühl brauchen wir gar nicht reden. Es kommt eben auch hier ein globaler Mittelwert an Text heraus.
Abgesehen vom grundsätzlich noch immer besseren Ergebnis ist DeepL auch was Datenschutz und Urheberrecht angeht sinnvoller als Google oder andere Lösungen. DeepL ist eine deutsche Seite, die Firma dahinter sitzt in Köln. Das heißt mit Blick auf Dateneigentum und Datenschutz: Ist in Europa (sogar in Deutschland), also schonmal super. Mit dem Pro-Account hat man auch die Möglichkeit, ganze Dokumente automatisiert übersetzen zu lassen. Und vor allem sind diese dann auch wieder vom Server gelöscht, sobald die Übersetzungen heruntergeladen wurden. Also super Datenschutz auch für Firmen oder Menschen, die beruflich damit arbeiten. Einen Auftragsverarbeitungsvertrag nach DSGVO gibt es natürlich auch.
DeepL Übersetzer ist grundsätzlich gratis über die Webseite verwendbar. Der Pro-Account lohnt sich aber meines Erachtens hier sehr. Dabei sind 5 Dokument-Übersetzungen pro Monat inbegriffen, mehr können zugekauft werden. Bei monatlicher Zahlung sind es € 8,99, bei jährlicher Zahlung € 7,49. Es gibt auch noch größere Pakete für Firmen.
Zum Thema sexistische oder rassistische Schieflage in Algorithmen und ihren Trainingsdaten habe ich neulich auch bei DeepL einen Fall gefunden, als ich eine Kurzgeschichte aus dem Englischen ins Deutsche übersetzt habe. Aus dem englischen Satzteil "before outlining the discovery of the DNA double helix by Watson and Crick" machte DeepL "bevor er die Entdeckung der DNA-Doppelhelix durch Watson und Crick darlegt" und unterstellt damit, dass die handelnde Person in der Szene ein Mann wäre. Es geht aber im konkreten Fall um eine Biologie-Lehrerin.

Im Screenshot seht ihr übrigens die lokal installierte Version von DeepL. Die hat vor allem den Vorteil, dass man einen Textteil markieren kann und per Tastendruck direkt einen Vorschlag bekommt, ohne über den Browser zu gehen. Aber auch die lokale Installation brauch eine Verbindung zum Internet, sonst sagt es nur, dass es den Text nicht übersetzen konnte. Es spart also keine Ressourcen ein. Schade eigentlich.
Ein grundsätzlicher Nachteil von KI-Übersetzungen ist: Je mehr Texte per KI "erstübersetzt" werden und dann "nur noch" von einer Lektorin bearbeitet, desto gleicher werden die übersetzten und dann veröffentlichten Texte. Das liegt daran, dass KI-Übersetzungen weniger stilistische Varianz enthalten. Menschliche Übersetzende bringen mehr Eigenleistung in den Text – weshalb ja auch durch Menschen geschaffene Übersetzungen ein Urheberrecht haben. Nicht so die KI-generierten Übersetzungen, die im Falle von Englisch ein "blutleeres globales Englisch" produzieren, um meinen Sitznachbarn im Zug von Frankfurt bis Nürnberg neulich zu zitieren. Dieser "Einheitsstil" ist – meines Erachtens – durchaus erkennbar, sowohl bei Übersetzungen als auch bei generierten Texten allgemein. Der Wiedererkennungswert geht vom "unverkennbar dieser Autor / diese Marke / diese Übersetzerin" über in "unverkennbar KI-generiert".
KI-Übersetzung Don't
- Von einer KI übersetzte Texte ungeprüft einfach so veröffentlichen
- KI-Übersetzungen verschweigen
KI-Übersetzung Do
- Übersetzung und insbesondere sachliche Details überprüfen
- Übersetzungs-Hilfe mit KI im Impressum des Buchs oder unter dem Artikel/Blogpost ausweisen, damit Lesende wissen, worauf sie sich einlassen
- DeepL Pro-Account nutzen für mehr Datenschutz
- optional: DeepL lokal installieren für Shortcuts per Tastendruck
KI-Übersetzung Trade-off
- Verlust von Sprach-Eleganz und Varianz im übersetzten Text
- Kostet neben Geld außerdem in etwa soviel Wasser und Strom wie eine KI-gestützte Suchabfrage
Bildgenerierung und -analyse
Bilder generieren ist sehr einfach und zugänglich geworden. Und auch dabei gibt es sinnvollere und weniger sinnvolle Einsatzzwecke. Grundsätzlich gilt, dass Bilder generieren zu lassen mehr Strom und Wasser verbraucht als Text generieren zu lassen. Und das für Bilder, deren "Stil" für viele Nutzenden erkennbar KI-generiert und daher oft schon ermüdend ist – denken wir noch einmal an den Charme von Plastikbesteck. Dennoch kann Bildgenerierung für uns als Autor:innen hilfreich sein.
This person does not exist
Wenn wir unsere Bücher mit Charakteren und deren Leben füllen, stellen wir uns öfter mal Schauspieler:innen vor oder die nette Verkäuferin in der Bäckerei oder auch mal den komischen Nachbarn mit seiner unaufhörlichen Begeisterung für Laubbläser. (Okay, vielleicht mache auch nur ich das ...) Grundsätzlich ist es klug, keine echten Personen in Bücher zu schreiben, da es so etwas wie Persönlichkeitsrechte gibt und wir als Autor:innen nicht gerne verklagt werden. Also brauchen wir Figuren, die nicht nebenan (oder auch sonstwo auf der Welt) leben und bei denen sich Menschen nicht direkt angesprochen fühlen. Dabei kann uns ein Random Face Generator helfen. Oder auch: Diese Person existiert nicht.
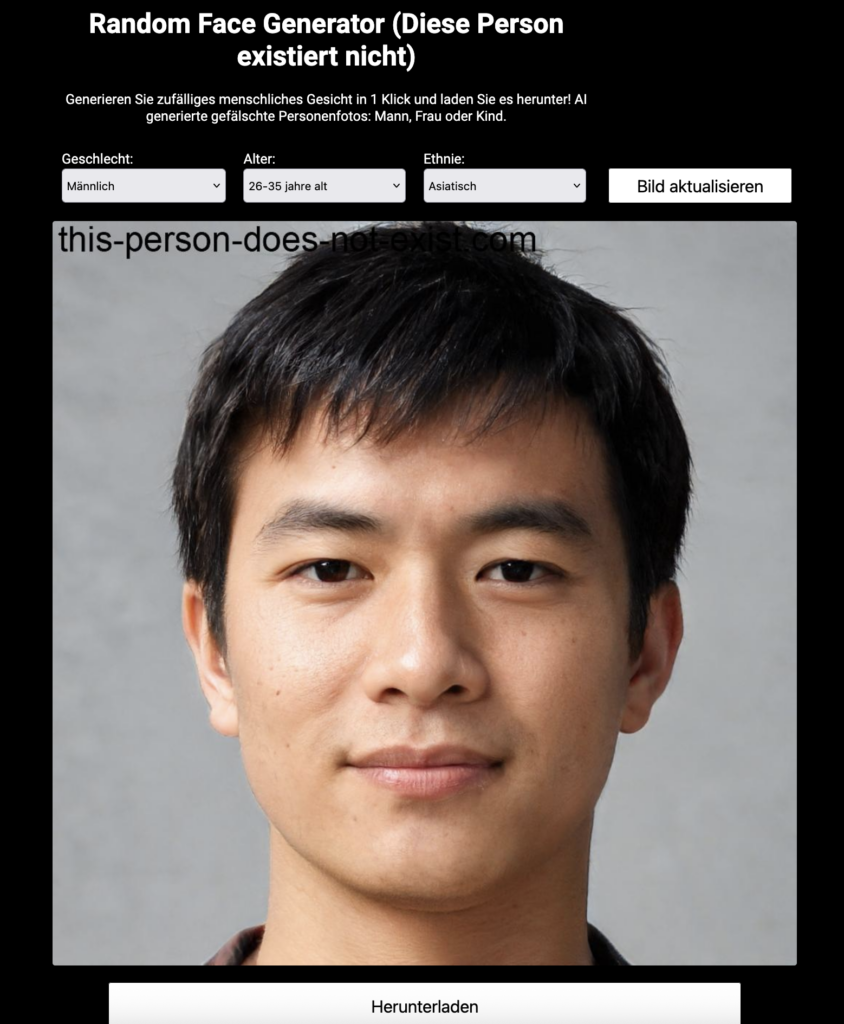
Wer vielleicht auch noch ein paar Haustiere dazusetzen möchte, kann auch von den eigenen Katzen ablassen und die Webseite These Cats Do Not Exist dafür verwenden. Es gibt auch genug Bilder dort, um ein ganzes Katzen-Café mehrfach neu zu besetzen. ;)
Bilder generieren mit ChatGPT
Ja, ChatGPT kann auch Bilder generieren und das klappt auch erstaunlich gut. Midjourney macht einen noch besseren Job dabei, aber grundsätzlich kann man damit arbeiten. Insbesondere, wenn man multimodal arbeiten möchte, also sowohl mit Texten als auch mit Bildern.
Prompt:
Bitte erstelle mir ein Bild einer Tasse Kaffee. Das Setting ist eine Konferenz von Krimiautor:innen.

Das Erstellen von Bildern dauert länger als das Erstellen von Text. Auch keine Stunden, aber eine Minute oder so kann es schon werden.
In dem Fall haben wir vor Ort im Workshop ein Bild einer Kaffeetasse bei einer Konferenz von Krimiautor:innen erstellen lassen und die Teilnehmenden waren vor allem überrascht davon, wie lange es gedauert hat. Und danach dann von der Mittelmäßigkeit der Tasse. ;) Aber auch in dem Fall wird das wahrscheinlichste Motiv berechnet und erstellt.
Man kann auch mit dem Modell interagieren und Anweisungen geben, das Bild abzuändern. Hintergrund heller/freundlicher/im Regen ... Oder Tasse in blau, gelb, geblümt ... Es sind der Phantasie keine Grenzen gesetzt, dem Modell gelegentlich allerdings schon. Manchmal stößt man auf Grenzen, wo es einfach nicht weiter tut. Und ab und an verliert es auch einfach den Faden.
Auch Claude kann Bilder erstellen, allerdings nicht in dem Maß wie ChatGPT. Mistral kann es im angemeldeten Bereich.
Außerdem solltet ihr euch Midjourney ansehen, wenn ihr mehr mit Bildgenerierung machen wollt. Bei Midjourney geht das Prompten allerdings via Discord, ihr braucht also einen Account dort, um via Discord-Chat die Prompts an Midjourney schicken zu können. Discord ist eine US-Chat-Plattform, muss man also auch eher wollen. Außerdem sind sowohl eure Prompts als auch die generierten Bilder bei Midjourney für alle anderen Nutzenden sichtbar und können auch von jedem:r verwendet werden. Aber das mit dem Urheberrecht auf generierte Inhalte und den fehlenden Einmaligkeitswert (USP, Unique Selling Point) hatten wir schon.
Achtung! Ihr könnt bei allen Modellen auch Bilder als Referenz hochladen (für den Stil, wie die Person aussieht etc.). Denkt dran, dass ihr damit Informationen an die Unternehmen der Modelle verschenkt (ggf. automatisch an die Plattformen lizenziert). Außerdem denkt dran, dass ihr im Falle von Bildern von Menschen personenbezogene Daten an – zumeist – ein US-Unternehmen rausgebt. In DSGVO-Sprech: Drittstaaten-Transfer von sensiblen Daten, denn unsere Gesichtsbilder sind sensible Daten (in DSGVO-Sprech: besondere Kategorien personenbezogener Daten). Dazu braucht ihr immer die Einwilligung der Betroffenen. Ladet keine Bilder hoch von Menschen, von denen ihr kein explizites und am besten schriftliches Einverständnis habt!
Bilder "passend machen"
Viele Modelle bieten die Möglichkeit, Bilder in bestimmte Formate zu bringen – Hochformat in Querformat oder umgekehrt – und die fehlenden Teile algorithmisch zu ergänzen. Das können auch die Programme von Adobe oder die Online-Bildbearbeitung Canva.
Aber Vorsicht! Die generierten Teile können stark von der Vorlage abweichen und das Motiv verändern.
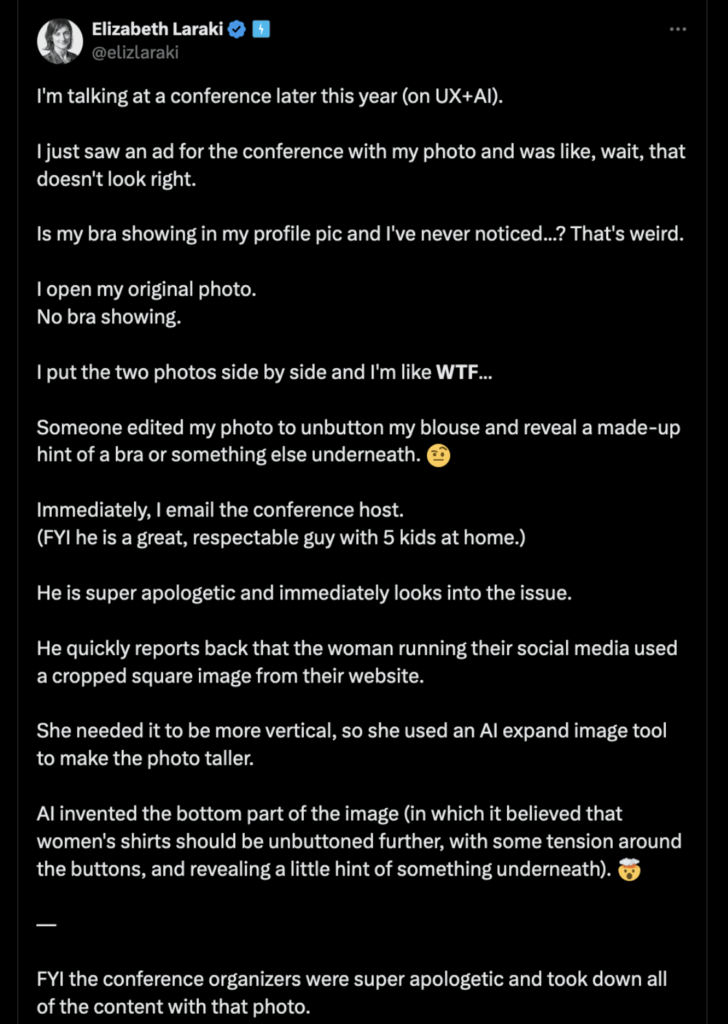
Da gibt es das Beispiel der Vortragenden, die für ihre Konferenzteilnahme ein Sprecherinnenfoto eingereicht hat und dann im Fahrplan der Konferenz ein Bild von sich sah mit hervorblitzendem BH und mehr Busen, als sie eigentlich hat. Es stellte sich raus, dass die Veranstalter KI verwendet hatten, um das Bild umzuformatieren, wobei das Modell der Vortragenden direkt an die Bluse ging.
Das Bild wurde – leicht aber doch – sexualisiert. Einer von unzähligen Hinweisen auf die sexistische und rassistische Schieflage in den Trainingsdaten der Algorithmen. Frauen werden en gros tendenziell sexualisiert dargestellt, also macht auch das Modell aus einem Bild einer Frau eine (leicht) sexualisierte Darstellung.
Hier ihre Gegenüberstllung. Links das Originalbild, ein scharfes Foto, die Frau mit goldener Kette und mit Taschen an der Bluse. Rechts schwarz-weiß mit Weichzeichner, ohne Taschen an der Bluse, dafür ein hervorblitzender BH und ein paar mehr Falten im Stoff, was die Oberweite voller aussehen lässt.

Bildanalyse mit Perplexity
Bei Perplexity kann man Bilder hochladen und analysieren lassen. Das geht mit dem Büroklammer-Symbol neben dem Eingabefeld.
In einem Kurs, in dem ich war, hat der Kursleiter ein altes Foto von sich selbst hochgeladen und Perplexity gebeten, das Bild zu datieren. Das hat das Modell auch getan – anhand der Wanderschuhe, die auf dem Bild halbwegs zu erkennen waren. In welchem Zeitraum wurden die hergestellt? Plus der restliche Kleidungsstil und die Farben des Bildes – et voilà: späte Achtziger bis frühe Neunzigerjahre des 20. Jahrhunderts. Stimmte seiner Aussage nach.
Man kann aber auch zB ein Foto eines Dings hochladen und Perplexity nach einer Bedienungsanleitung dafür suchen lassen, etc. Also grundsätzlich kann das durchaus nützlich sein.
Ich selbst habe schon ein von ChatGPT generiertes Bild eines skandinavischen Dorfs hochgeladen und eine Bildbeschreibung generieren lassen. Außerdem habe ich Perplexity gefragt, wo das Dorf wohl sein könnte. Die Antwort war ebenfalls etwas Skandinavisches. Aber es ist davon auszugehen, dass das Bild auch entsprechend "maximal mittelmäßige skandinavische Dörflichkeit" zeigt. ;D
Nazi-Inhalte und "Fan-Artikel" erkennen
Gut, dazu braucht man keine KI, aber diese Plattform ist super hilfreich a) um nicht versehentlich zwischen den Millionen KI-generierten "lustigen" T-Shirt-Motiven eins zu erwischen, das vielleicht hübsch gemacht ist mit einem harmlos klingenden Spruch, der aber tatsächlich eine Nazi-Dogwhistle darstellt. Und b) kann man das auch mal für eine Recherche verwenden. Fashion against Fascism ist die größte Online-Datenbank gegen Nazi-Codes.
KI-Bildgenerierung Don't
- KI-generierte Bilder im Übermaß verwenden
- Generierte Bilder nicht als solche ausweisen
KI-Bildgenerierung Do
- KI-generierte Bilder kenntlich machen
- Überprüfen, ob Bilder mit einer sexistischen oder rassistischen Schieflage generiert wurden
KI-Bildgenerierung Trade-off
- Strom- & Wasserverbrauch ist pro generiertem Bild enorm, auch bei denen, die nicht verwendet und "weggeworfen werden"
Multimodales Arbeiten mit ChatGPT
Was ich gerne mit Jugendlichen mache ist, dass ich sie zuerst ein Unternehmen erfinden lasse. Dieses Unternehmen arbeiten wir dann mit Hilfe von ChatGPT etwas weiter aus.
Prompt:
Du bist Marketingexperte und sollst mir helfen, eine Marketingkampagne aufzusetzen. Es geht um eine Zahnarztpraxis, die ein neues Programm für Angstpatient:innen einführen will. Bitte gib mir ein paar Ideen für Werbematerial auf verschiedenen Kanälen.

Dann erstellen wir dafür sowohl eine CI (Corporate Identity in Sprache und Bild) und dann eine Werbekampagne für ein Event dieses Unternehmens inkl. Texte und Motive und das Ganze dann auf Flyern, Plakaten etc. Wir lassen uns auch immer eine ganze Marketing-Strategie mit verschiedenen Kanälen, Out-of-Home etc. vorschlagen.
Was ChatGPT mit dem Dall-E Modell an Bildern generieren kann, ist schon sehr nett, manchmal beeindruckend, oft eher amüsant. Aber bei der Werbekampagne für eine Zahnarztpraxis, die auf Angstpatient:innen spezialisiert ist, ein Bild wie dieses zu generieren, war auch eher ... speziell.
Außerdem kriegt man auch wieder nur Vorschläge für Werbemaßnahmen dabei heraus, die in den letzten 20 Jahren von Marketingagenturen zementiert wurden (weil die damit Geld verdienen), aber keine kreativen, tatsächlich neuartigen Ideen.
Hier ein solcher multimodaler ChatGPT-Verlauf aus März 2025. Klick auf's Bild für eine lesbare Ansicht. Auch immer wieder hübsch: ChatGPT und Schrift in Grafiken ...
KI & Audio
Speech to Text – automatische Transkripte & Diktieren
Was schon seit einer Weile auf Plattformen wie Auphonic (Österreich) geht, ist gesprochenes Wort in geschriebenen Text transkribieren zu lassen. Auphonic macht automatisierte, algorithmenbasierte Audio-Postproduction. Zwei Stunden Audio-Länge hat man pro Monat gratis, darüber hinaus gibt es entweder ein Abo oder Stundenpakete. Ich bin mit letzteren bisher sehr gut gefahren. Viele Podcastende verwenden Auphonic, um ihre Aufnahmen automatisiert verbessern zu lassen (Lautstärkenanpassung (Normalisierung), kleiner Booster für menschliche Stimme (Equilizer) etc.) Aus dem Bereich kenne ich das auch und nutze es sehr gerne. Auch für Video- und Hörbuch-Postproduction ist der Service wirklich Gold wert. Einen AVV nach DSGVO bekommt man dort natürlich ebenfalls.
Bei Auphonic kann man mit der automatischen Tonverbesserung auch gleich ein Transkript der Audiodateien anfordern. Das kostet nichts extra und ist wirklich schon richtig gut und wird auch immer noch besser.
Jetzt geht automatisches Translkribieren dank OpenWhisper auch lokal auf dem Rechner. Hersteller ist OpenAI, also die Firma hinter ChatGPT, aber OpenWhisper ist Open-Source und es gibt mittlerweile viele Programme, die diese Technologie verwenden, einige auch ganz brav lokal auf dem Rechner, ohne dass Daten erhoben oder gar irgendwo hin geschickt werden. Das hilft natürlich enorm bei vertraulich geführten Gesprächen. Ich habe beispielsweise für das Women in Tech Buch über 20 Interviews geführt, von denen einige nicht veröffentlicht werden sollen. Da gilt natürlich Quellenschutz. Wenn aber das Modell rein auf meinem Rechner läuft und ausgeschlossen werden kann, dass die Stimmdaten und gesprochenen Inhalte ins Netz fließen, kann ich diese Interviews aber so auch transkribieren lassen und spare mir ein paar Stunden des reinen Mittippens.
Auf dem Mac verwende ich dafür WhisperNotes, das einmalig € 4,99 gekostet hat. Schaut einfach, welche OpenWhisper-Programme es für euer Betriebssystem gibt und welche davon keine Daten erheben oder ins Netz schicken. Der Apple AppStore macht es einem ja mittlerweile erfreulich leicht, das auf den ersten Blick zu sehen.
In WhisperNotes kann man entweder Audio-Dateien wie MP3-Dateien reinladen, um sie transkribieren zu lassen. Man kann aber auch diktieren und bekommt ein automatisches Transkript des Gesagten.
Diktieren
Ich weiß nicht, ob noch jemand Dragon verwendet. Ich fand es immer sehr umständlich, damit zu arbeiten. Aber das ist wohl auch mein Sturkopf und die Erwartung, dass das Programm irgendeien Form von Flexibilität mit sich bringt. Wer mit Dragon klarkommt, ist damit sicher noch immer glücklich zu machen.
Ich probiere seit ein paar Jahren immer wieder mal aus, wie weit die On-Board-Transkripte von Apple selbst sind. Denn auch hier kann man einfach reinsprechen und das Betriebssystem setzt die Sprache in geschriebenen Text um.
Die Funktion findet ihr in den Einstellungen bei Tastaturen – Diktierfunktion.
Bei mir ist die Diktierfunktion auf der rechten Command Taste. An sich ist das schon wirklich ganz praktisch aber man muss noch immer Punkt und Komma dazu sagen. Ah nein, diesmal hat er sowohl das, als auch den Punkt selbsttätig gesetzt, dass ja auch schon mal eine große Hilfe.
Die Diktier-Funktion gibt es auch auf iPad und iPhone.
Text to Speech
Aus geschriebenem Text gesprochene Sprache zu machen, war viele Jahre ein Ding, das wir mit "Roboterstimme" assoziiert haben. Zu Recht. Und wenn man allein auf dem Mac an die alte "dumme" Siri denkt, die mit Roboterstimme Texte "vorliest", dann war das bis vor ein paar Jahren auch so. Mittlerweile ist schon die normale Siri-Stimme recht gut. Ihr könnt es auf dem Mac ausprobieren. In den Einstellungen bei Bedienungshilfen könnt ihr bei "Gesprochene Inhalte" beispielsweise "Auswahl sprechen" aktivieren und dann mit Klick auf das Info-"i" eine Tastenkombination festlegen, mit der etwas vorgelesen werden soll.
Automatisch generierte Hörbücher
Es geht aber bereits um Welten besser. Seit einigen Jahren kann man "automatisch vorgelesene", also von Software synthetisierte Audioinhalte auf verschiedenen Hörbuchplattformen anbieten. Die letzten, die sich noch gesträubt hatten, waren Amazon und die rollen gerade ihre eigene AI Voice Narration aus, die 2024 noch in der Betaphase für einige wenige Selfpublisher:innen im englischsprachigen Bereich war. Allerdings dürfen die damit generierten Hörbücher ausschließlich auf Amazon angeboten werden.
Bei Google ist es schon seit Jahren möglich, aus eBooks Hörbücher generieren zu lassen, wenn man die eBooks via Google Play Books veröffentlicht. Der große Pluspunkt ist, dass es bei Google möglich ist, die generierten Files zu nehmen und auch auf anderen Plattformen zu verkaufen. Das geht auch in anderen Sprachen als Englisch und ist bislang kostenlos – also zumindest ohne Geldzahlung, andere Kosten wie Privatsphäre, Auswertung des Nutzungsverhaltens etc. gibt es natürlich bei Google immer. So habe ich beispielsweise ein generiertes Hörbuch für das Datenschutzbuch erstellt, was mit ca. einem Tag Aufwand viel schneller geht, als es selbst einzusprechen – durchaus interessant für ein Buch, das ich ca. alle anderthalb Jahre aktualisiere und das dann immer neu eingesprochen werden müsste. Und der Blindenverband, für die ich auch schon Workshops gegeben habe, hat sich sehr gefreut. Für "fertige" Bücher, also welche, die sich nicht mehr ändern, würde ich das allerdings persönlich nicht in Betracht ziehen.
Elevenlabs hat was AI Voice angeht seit Jahren die Nase vorn. Das war jetzt jahrelang der Goldstandard und die von Elevenlabs generierten Stimmen sind wirklich gut und von den meisten Hörbuchplattformen auch akzeptiert. Elevenlabs bietet sowohl Text to Speech als auch Speech to Text.
Automatisch erstellte "Podcasts"
Okay, das ist der eine Google-Fall, den ich euch erzählen wollte. Kurz gesagt: Crazy as Sh*t.
Bei Google NotebookLM kann man eigene Quellen wie Bücher, PDFs, Texte ... hochladen und mit diesen Quellen interagieren, die zusammenfassen lassen, nach bestimmten Themen auswerten etc. An sich super cool, nur leider von Google (siehe oben: nicht unser Freund). Genau sowas hätte ich gerne lokal auf meinem Rechner ohne dass Daten an irgendeinen US- oder sonstigen Service gehen.
Und dann hat NotebookLM noch diese kleine Schaltfläche oben rechts: "Audio-Zusammenfassung erstellen". Und weil Joanna Penn so davon geschwärmt hat, war ich neugierig und habe Google die Rohfassung des Vorworts für die kommende Auflage des Datenschutzbuches gegeben und es mal machen lassen.
Das habe ich als reine Textdatei auf Deutsch reingefüttert:
Während in der Politik seit Russlands Angriffskrieg auf die Ukraine von einer Zeitenwende gesprochen wird, haben wir im technischen Bereich ebenfalls eine Zeitenwende erreicht, die um so sichtbarer wird, seit in den USA Trump zum zweiten Mal das Präsidentenamt eingenommen hat und die Riege an Silicon-Valley-Milliardären der Reihe nach ihren Kniefall vor ihm macht. Mit einem Mal stehen wir vor dem Schlamassel, vor dem Menschen it IT-Security und Datenschutz seit vielen Jahren warnen: Unsere Abhängigkeit von US-Services fällt uns zusehends auf die Füße. In den USA sind auf Geheiß der aktuellen Regierung bereits im Februar 2025 Bücher aus den Regalen und Onlineshops verschwunden, die queere Charaktere oder starke Frauenfiguren beinhalten (Book Bans). Die Autor:innen solcher Bücher werden nicht mehr zu Lesungen eingeladen oder sogar ausgeladen, weil die Veranstaltenden Angst haben, mit einem solchen Auftritt den Unbill der Regierung auf sich zu ziehen. Trans-Personen können ebenfalls seit Februar 2025 nicht mehr einfach so in die USA einreisen, insbesondere dann nicht, wenn sie einen geänderten Geschlechts- bzw. Namenseintrag im Pass haben. Und auch wer jetzt denkt: »Das betrifft mich ja nicht«, dem sei gesagt, dass das ja nur der Anfang ist. Denn so wie Frauen in den USA, die nach Möglichkeiten für Schwangerschaftsabbrüche suchen dort vor Gericht gestellt werden und dafür alles herangezogen wird, was online an digitalen Spuren nur auffindbar ist – von privaten Nachrichten auf Social Media über Suchanfragen, Such-Historie, Maps-Einträge, Produkt-Suchen und einiges mehr – kann es auch uns in Europa jederzeit ereilen. Lassen wir es zu, dass einer der vielen Möchtegern-Autokraten hier bei uns seine Finger auf all unsere Daten kriegt, stehen wir genauso blank da wie all die Frauen und Autor:innen, die Trans-Personen und alle anderen, denen es auf der anderen Seite vom Teich bereits an die Existenz geht. Und so wie die neue rechtslastige nominell konservative Regierung in Deutschland bereits an Tag Eins damit angefangen hat, NGOs einzuschüchtern, ist das Szenario konkreter Verfolgung aufgrund unserer Daten nicht weit. Von der Umsetzung der von der rechten FPÖ in Österreich geforderten Abschiebungen durch die dortige konservative Regierung jetzt im Frühjahr 2025 ist es ebenfalls nicht weit zu Berufsverboten für Ungenehme und alles, was danach noch kommt. Und glaubt mir, mir wäre lieber, all diese Szenarien wären in dystopischen Büchern geblieben. Umso wichtiger wird es, sich mit der eigenen Privatsphäre und allem was ihr zuträglich ist, zu beschäftigen.
Während bei der letzten Ausgabe noch KI das große Thema war, haben sich die meisten von uns mittlerweile dran gewöhnt, dass die LLMs meistens »Stuss reden«. Trotzdem habe ich das Kapitel zu KI und was die Dinger mittlerweile können (und was alles nicht) deutlich überarbeitet. Und auch wenn die US-Regierung wieder in Träumen von Crypto-Reserven in Bitcoin schwelgt, bleibt das Kapitel dazu draußen und ist weiterhin auf meiner Webseite als zusätzlichen Download zu finden.
Willkommen im neuen Normal. Willkommen bei eurem persönlichen Begleiter in ein sichereres Leben.Vorwort (Entwurf) der 6. Auflage "Dann haben die halt meine Daten. Na und?!"
Denselben Text habe ich auch Elevenlabs gegeben, die ebenfalls eine Funktion "Podcast" haben, die mehr oder weniger dasselbe macht.
Was Elevenlabs daraus gemacht hat:
Elevenlabs bietet verschiedene Stimmen, unter anderem auch deutsche an, aus denen man auswählen kann. Ich habe absichtlich eine weibliche Stimme als Haupt"sprecherin" ausgesucht. Die Inhalte werden analysiert und in einem gut verständlichen Dialog verwandelt, der mit dem Originaltext nicht mehr viel zu tun hat. Man hat außerdem die Auswahl zwischen einem kurzen Dialog, mittlerer Länge oder lang, wobei alle dreii nicht so lang wurden wie das Ergebnis bei Google NotebookLM.
Was Google NotebookLM aus demselben Text gemacht hat – man beachte, dass es aus dem deutschen Ausgangstext eine neglischsprachige Audio-Zusammenfassung gemacht hat. Zu dem Zeitpunkt gab es nur Englisch, seit Mai 2025 ist auch Deutsch als Zielsprache möglich. Also:
Abgesehen von dem offensichtlichen sexistischen Bias, dass der Typ der Frau die Welt erklärt und sie die meiste Zeit nur "aha, aha" sagt, ist das suuuper creepy, von Google diese Inhalte "vorgelesen" zu kriegen. Aber es ist ja nichtmal vorgelesen, sondern der deutsche Text wurde auch hier analysiert, es wurden weitere themenverwandte Inhalte hinzugezogen und 5.48min englischsprachiges Audio daraus generiert. Das ist schon beeindruckend.
Es ist noch immer nicht kreativ in dem Sinne, sondern genau das, was ChatGPT und Co (und in diesem Falle die Google KI) eben tun: analysieren, weitere Informationen aus ihrem Datenpool heranziehen (da kommt auch der oben genannte Zufallsfaktor ins Spiel), daraus einen neuen Text generieren und in diesem Fall im Ausgabeformat "lockeres Gespräch" aufbereiten und mit zwei synthetisierten Stimmen ein menschliches Gespräch nachahmen. Aber nichtsdestotrotz: beeindruckend.
Musik generieren
Man kann auch Musik generieren lassen. sunoAI und Udio sind zwei bekannte und verbreitete Plattformen dafür, die mir auch immer wieder von Jugendlichen genannt werden, die damit herumexperimentieren.
Man kann bei beiden einen Liedtext eingeben (oder einen automatisch generieren lassen), den gewünschten Musikstil beschreiben (Genre, Stil, Stimme(n), Instrumente etc.), dem Song einen Titel geben und schon geht's los.
Telefon- und Videokonferenzen mit KI
Das ist jetzt eher der Themenbereich "Was heute schon alles möglich ist" und vielleicht eher in den RechercheOrdner für Krimiautor:innen zu schieben. Aber es ist nicht lang her, da hätte ein Security-Unternehmen beinahe einen Entwickler eingestellt, der gar nicht existiert.
"A full-remote security startup nearly hired a backend engineer who doesn’t exist, after a candidate used an AI filter as an on-screen disguise in video interviews. Learnings for tech companies"
Zur Kasse, bitte!
Verbrauche verschiedener KI-Anwendungen pro Anfrage
Ich habe Perplexity gefragt, mir bei der Auswertung der Strom- und Wasserverbräuche zu helfen. Lange hatten wir für Anbieter wie ChatGPT gar keine oder nur die Zahlen für das Training von deren Ki-Modellen, was natürlich nach ein paar Tagen oder einem Monat dann vorbei ist und nichts über den täglichen Betrieb der Systeme aussagt. Dank der Studie von Huggingface und den veröffentlichten Zahlen für ihre Open-Source-Modelle, können wir jetzt zumindest hochrechnen, was KI-Systeme an ökologischem Impact bedeuten. Zum Glück gibt es dazu mittlerweile immer mehr Artikel, die das Problem sichtbar machen, zB:
Bing-KI ist ein riesiger Stromfresser (August 2023)
Making an image with generative AI uses as much energy as charging your phone (Dezember 2023)
ChatGPT braucht 10-mal soviel Strom wie Google (August 2024)
ChatGPT: Enormer Energiehunger (September 2024)
Is AI eating all the energy? (Part 2/2; Direktlink zum Wasserverbrauch; September 2024)
AI’s Power Demand: Calculating ChatGPT’s electricity consumption for handling over 365 billion user queries every year (Januar 2025)
Making AI Less "Thirsty": Uncovering and Addressing the Secret Water Footprint of AI Models (März 2025)
Für einige Anwendungsfälle liegen leider noch immer keine Zahlen vor, in dem Fall hat Perplexity aus vorliegenden Zahlen hochgerechnet. Für KI-gestützte Suchanfragen gibt es seit diesem Jahr eine neue Studie, die zu weit niedrigeren Werten kommt, die ich noch nicht glaube, daher sind diese Zahlen in Klammern. Für die Gesamtrechnung gibt es daher einen von-bis-Wert.
Datenbankbasierte Suchanfrage
pro Anfrage: 0,3 Wattstunden (Verbrauch einer LED-Lampe für etwa eine Minute)
+ 0,5 Milliliter Frischwasser
-> 0,2 Gramm CO₂
KI-Suche via Perplexity
pro Anfrage: (0,3 bis) 2,9 Wattstunden
+ ca 100-500 Milliliter Frischwasser (unterschiedliche Zahlen im Umlauf)
Texterstellung
Kurze Textabfrage (GPT-4)
pro Anfrage: (0,3 bis) 2,9 Wattstunden (Verbrauch eines LED-TV-Geräts für 3,5 min)
+ 100-500 Milliliter Frischwasser (unterschiedliche Zahlen im Umlauf)
-> 4,32 Gramm CO₂
Lange Textabfrage (10.000 Tokens)
ca. (2,5 bis) 8 Wattstunden
Sehr lange Textabfrage (100.000 Tokens)
bis zu 40 Wattstunden
Reasoning Modelle verbrauchen voraussichtlich mehr; was ich jetzt mehrfach gelesen habe: ca. Faktor 5-10 im Vergleich zur Texterstellung per KI.
Bildgenerierung
pro Bild: 10 Wattstunden (einmal Smartphone voll laden)
+ 0,5 bis 1 Liter Frischwasser (hochgerechnet von Perplexity aus den Zahlen für die Textgenerierung)
-> 5–10 Gramm CO₂
Videogenerierung
pro Minute Video: 50 Wattstunden pro Minute Video (einmal vollen Wasserkocher zum Kochen bringen)
+ eine nicht dokumentierte Menge Wasser
-> eine unklare Menge an CO₂
Perplexity hat hochgerechnet: bei 30fps (Bilder pro Sekunde) wäre ein einminütiges Video = 1.800 Bilder und damit schon bei einem Verbrauch von 900 bis 1.800 Litern Wasser. Das halte ich auch wieder für nicht ganz glaubwürdig, aber es liegen keine belastbaren Zahlen für Video-Generierung zum Vergleich vor.
Audiogenerierung & Sonstige
pro Anfrage: 5–10 Wattstunden pro Anfrage
+ 1-2 Liter Frischwasser (da keine Zahlen vorliegen hochgerechnet von Perplexity)
-> eine unklare Menge an CO₂
Für diese Übersicht an Energie- und Wasserverbrauchen habe ich Perplexity 24 Fragen gestellt und damit zwischen 7,2 und 69,6 Wattstunden an Strom und zwischen 2,4 und 12 Liter Wasser verbraucht. Mit dem verbrauchten Strom hätte ich ein Smartphone mit 10Wh Akku-Kapazität zwischen einmal um 72% laden und bis zu knapp 7mal voll aufladen können. Und die mindestens 2,4 Liter Wasser hätte ich besser selbst getrunken ...
Tipps
Mitunter bekommt man sehr lange Informationstexte generiert und es ist hilfreich nach bestimmten Dingen dann mit Strg+F das Ergebnis zu durchsuchen, statt noch einmal eine Nachfrage zu stellen.
Und statt euch jedes Mal wieder einen Blindtext neu generieren zu lassen weil es ja so einfach geht, könnt ihr euch einmal einen Lorem Ipsum Generator suchen und den Text in verschiedenen Längen auf eurem Rechner abspeichern und schon habt ihr einen wiedererkennbaren Platzhaltertext und dabei auch jede Menge Strom und Wasser gespart.
Und diese eine Vokabel, die ihr jedes Mal wieder nachschlagt – schreibt sie euch doch einfach mal auf. Genauso wie das geheime Waffelrezept von Chefkoch. ;)
Dieser Blogbeitrag wurde per Hand von der Autorin selbst verfasst.
Stand: 10. Mai 2025
You may also like:

Update zu Transparenzpflichten nach KI-VO
Die Aufregung um die Transparenzpflichten scheint in einigen Teilen der Publikationslandschaft hoch zu sein. Andere haben vielleicht noch gar nicht mitbekommen, dass da etwas kommt. Und von wieder anderen hörte ich schon: "Das sollen die mir erstmal nachweisen!" ... Nun ja. Aktuell sieht es so aus:

"KI-resistente" Workflows für Lektorat, Kommunikation, Zusammenarbeit etc.
Beim Hochladen auf Vertriebsplattformen, seien es Selfpublishing-Anbieter wie Tredition oder KDP oder...

#SaveSocial – für ein demokratisches Internet
Instagram: venture capital, staatsnahe Platform USA. Facebook: venture capital, staatsnahe Platform USA....

Social-Media Grundsätze: Wir haben Verantwortung für unsere Followerschaft
TL;DR: Wo wir sind, ist eine Aussage und beeinflusst ganz konkret, wo...

Eure Autor:innen-Webseite als KI-Trainingsgelände
... und was ihr dagegen tun könnt. Schlechte Nachrichten für alle, die...

Bezahlung nur bei mindestens 1.000 verkauften Büchern im Quartal?
Warnlampe am Horizont! Die Zahl ist fiktiv, das oder ein ähnliches Szenario...