

Hörbücher selbst aufnehmen – Teil 2: Nachbearbeitung & Publikation
Wie beim letzten Mal geschrieben, habe ich auch die Nachbearbeitung vom „Mord & Schokolade“ Hörbuch selber gemacht. Ganz ehrlich? Ich habe etwas gefunden, das ich gerne auslagern würde, sobald ich es mir leisten kann. Nicht, dass es nicht menschenmachbar wäre, andere schaffen das ja auch. Aber es macht mir einfach keinen Spaß. Vielleicht war es aber auch das viele Rumprobieren mit den teils herben Rückschlägen und ich finde da beim nächsten Mal noch mehr Gefallen dran. Man soll ja niemals nie sagen.
Die Nachbearbeitung
Ich hatte ja das Buch eingesprochen und bereits mit Rollback gearbeitet. Tatsächliche Textfehler waren beim Durchhören auch keine (mehr) drin, nur zweimal hab ich die Kapitelansage vermurkst und die hab ich dann nachgebessert. Und einen Satz hab ich neu eingesprochen. Das war der erfreuliche Teil. Ich war auch mit Stimmlage und Dynamik in weiten Teilen sehr zufrieden.
Was mich überrascht hat waren die Sprechgeräusche. Nachdem ich Magenknurren, Sabberbläschen, trockene Zunge und dergleichen ziemlich gut im Griff hatte und davon in der Aufnahme nichts mehr zu hören war, war ich schockiert, wie laut ich offensichtlich noch „Klack-Laute“ am Ende von Sätzen machen. Lieber Himmel! Das war wirklich Arbeit und ich hab sie auch nicht alle rausbekommen. Mit den 250-Ohm-Kopfhörern, die ich zum Schneiden verwende, war es wirklich schlimm, mit den 32-Ohm-Kopfhörern war es noch hörbar aber etwas erträglicher. Die Bose QC25 machen von sich aus mehr Bass und waren da am verzeihendsten. Und ich hoffe natürlich, dass die Hörer*innen nicht alle mit hochohmigen Kopfhörern ihre Hörbücher konsumieren.
Nach einem Durchgang, um die Pausen zwischen den Sätzen, Absätzen und Kapiteln ordentlich zu machen, habe ich ein MP3 aus meinem Reaper/Ultraschall rausgerendert, das ich dann Testhörer*innen zur Verfügung gestellt habe.
Danach folgte ein zeitlich längerer Umweg mit dem Versuch, das Audiomaterial automatisiert mit Auphonic abzumischen. Das große Problem und erste Learning war: Zu große Lautstärkeunterschiede schafft der Algorithmus nicht. Gut, das hätte ich mir auch denken können, jetzt weiß ich es und teile mein Wissen gerne, um Euch diesen Umweg zu ersparen.
Das erste Ergebnis war – in meinen Ohren – haarsträubend. Die Dialogteile, die laut sein sollten, waren leise, die die leise sein sollten, waren laut und alles dazwischen war abgehackt und in unregelmäßigen Abständen waren dann in der laufenden Spur auch zwischen den Dialogen „Lautstärkeaussetzer“ drin, wo es unvermittelt ganz leise und sofort ganz laut war.
Erster Versuch: gescheitert.
Timm Süss, der Hörspiel-Produzent aus der Podcaster-Szene, hatte mir dann noch geholfen und das Ausgangs-Audio durch seine Auphonic Standalone geschubst (mit allem, scharf und Gummibärchen) und dann noch ein bisschen Audio-Magie in Form von sehr teurer Software draufgeworfen. Das Ergebnis klang zwar von der Stimme her super, aber löste das eigentliche Problem leider nicht.
Zweiter Versuch: gescheitert. Zum Glück hatte ich nochmal über längere Strecken reingehört, im ersten Anlauf dachte ich nämlich schon, das hätte geklappt!
Der dritter Versuch war dann, die lauten Stellen in eine zweite Spur zu legen und die gesondert abzumischen. Die Idee wäre, beim nächsten Hörbuch dann alle Charaktere beim Schneiden dann in einzelne Spuren zu legen, damit man nach männlichen und weiblichen Charakteren gesondert bearbeiten kann und die Unterschiede in der Nachbearbeitung besser rauszuarbeiten. Die Idee an sich ist gut! Ich weiß allerdings noch nicht, ob ich das wirklich tun werde. Für das erste Hörbuch waren es dann zwei Spuren, die als Mehrspuraufnahme dann durch Auphonic gejagt wurden. Leider mit fast demselben Ergebnis.
Ohne den „Dynamic Leveler“ von Auphonic waren die Audio-Aussetzer weg und auch die „gegengleiche Lautstärke“ bei den Streit-Szenen war deutlich besser. Aber das Ergebnis war trotzdem wenig zufriedenstellend. Gerade die noch vorgandenen Klack-Laute an den Satzenden wurden durch den Algorithmus nur noch lauter und deutlicher. In der Zwischenzeit war der Georg von Auphonic schon mit involviert und schaute, was man aus dem Ausgangs-Audio rausholen konnte.
Letztlich lief es darauf hinaus, dass ich das gesamte Hörbuch noch einmal überarbeitet habe: Die Klacklaute so gut wie möglich rausgeschnitten, die lauten Bereiche direkt in der Spur rausgetrennt und leiser gestellt, sodass die Dynamik nicht verloren geht und man beim Hören noch immer das Gefühl hat, dass eine Person schreit, die andere versucht zu beschwichtigen, aber einem dabei nicht die Ohren wegfliegen.
Danach hab ich noch einen Versuch mit dem ersten Kapitel in Auphonic probiert. Georg hatte auch noch sachdienliche Hinweise, aber das Ergebnis war mir einfach zu „dumpf“.
Ich hab dann per Hand abgemischt – Gate Filter drauf, dass leise Nebengeräusche und leises Atmen rausnimmt, einen Kompressor, einen Soft Clipper/Limiter und einen EQ, der für „full vocals“ sorgen soll.
Mit dem Ergebnis bin ich so zu 90% zufrieden. Aber ich habe eingesehen, dass ich die Grenze dessen erreicht habe, was ich selbst leisten kann. Audiotechniker können da sicher noch viel mehr rausholen – also wenn man ein ordentliches Ausgangs-Audio liefert, natürlich!
Meins hatte beispielsweise im ersten Anlauf wie gesagt zu große Lautstärkeunterschiede. Aber selbst als ich die dann raus hatte, war das File am Ende noch immer zu leise. Das ist etwas, wo ich beim nächsten Mal ganz dringend drauf achten muss, dass die Eingangslautstärke schon passt.
Export für die Publikationsplattform
Wenn die Bearbeitung fertig ist, kommt der Teil, der mich über Gebühr frustriert hat. Die technischen Anforderungen an das Audio sind bei FindawayVoices jetzt keine Rocket Science:
- jedes Kapitel als einzelne Datei (max. 120min pro Kapitel; falls keine Kapitel vorhanden, ist das Audio in Abschnitte von 30 bis 120 Minuten zu teilen)
- 1 Sekunde Stille am Anfang des Kapitels
- 5 Sekunden Stille am Ende
- 192 kbps oder mehr
- 41.000 Hz
- Lautstärke zwischen -23dB und -18dB, Peakwerte unter -3dB und Maximum -60dB
- .flac (oder MP3, aber warum soll ich komprimiertes Audio liefern wollen, wenn es auch lossless geht?)
Die inhaltlichen Anforderungen sind ebenfalls relativ überschaubar:
- kein copyrighted Material oder irrelevanten Töne (Seitenblättern)
- am Anfang eines neuen Kapitels muss ein Indikator für ein neues Kapitel stehen
- Opening credits müssen den Titel sowie Autor*in und Sprecher*in nennen (und sonst nix, dafür aber alle (!) Sprecher*innen)
- es muss Closing credits geben, die das Ende des Buchs anzeigen. Optional kann man dort nochmal Titel, Autor*in und Sprecher*innen nennen, ebenso wie Copyright Info, etc.
- Front Matter und Back Matter sind optional, falls man Infos hat, die vor oder hinter das eigentliche Buch gehören
- man braucht ein Audiobook Sample für den Handel von weniger als 5 Minuten und ohne Musik, Credits oder Contenterklärungen
Bei anderen Plattformen verlangen sie auch mal .wav oder so, aber im Grundsatz ist es überall so ziemlich dasselbe, was ich gesehen habe. Möglichst hochwertiges, verlustfreies Audio kapitelweise rein plus ein Retail Sample.
So weit, so gut. Und dann kam ein Problem, was auf eine erhebliche Dissonanz meines Workflows und dem von Reaper/Ultraschall zurückfällt. Ich schreibe seit 2004 Bücher, seit 2008 Romane. Ich denke in Kapiteln. Reaper/Ultraschall exportiert aber nicht nach Kapitelmarken, sondern entweder einzelne Spuren so wie sie sind oder in Regionen. Mein Kopf explodierte an dieser Stelle mehrfach. Laut Reaper wäre also der Plan, dass jede Spur (bei mir ist das jedes einzelne Kapitel) vorne bei 0:00:00 anfängt. Tut es bei mir aber nicht, bei mir fängt das Kapitel eben dort an, wo das letzte aufgehört hat. Plus 6 Sekunden für die einzuplanende Stille. Weil Bücher eben linear sind – zumindest in meinem Kopf.
Die Alternative sind Regionen und das wollte so absolut nicht in meinen Kopf passen. Bei Podcasts exportiere ich immer die gesamte Länge und Auphonic teilt das schön bei der Kapitelmarke nach Kapiteln, wenn man das möchte. Bei Reaper musste ich dann also Regionen anlegen, damit die Kapitel einzeln exportiert werden konnten. Für mich ist das doppelt-gemoppelt. Für Musikproduzenten mag das Sinn ergeben, sich überlappen könnende Dinge einzeln exportieren zu wollen, für mich ist das 🤯 *BOOOOOOOMM*.
Über die gesamte Produktionszeit ist Reaper/Ultraschall mehrfach abgestürzt und vergaß Dinge, die ich vorher mit Strg+S gesichert hatte. So auch einmal die Regionen. Also alleine der Export hat mich einen Tag gekostet. Das hätte nicht sein müssen und nächstes Mal weiß ich das auch, aber es hat mich einfach geärgert.
Am Ende hatte ich 22 einzelne Audiofiles, von denen ich das erste Kapitel noch als Retail Sample einmal gekürzt habe.
Hochladen auf die Publikationsplattform
Die insgesamt 23 Dateien werden dann auf die Publikationsplattform geladen. Das geht einfach per Drag&Drop. No Magic here.
Wenn man dann auf „Absenden“ klickt, bekommt man einen Infobildschirm, der einem mitteilt, dass das hochgeladene Audiomaterial jetzt „eingeschlossen“ ist und einem internen Encoding sowie der Qualitätssicherung zugeführt wird. Außerdem werden die vorher ausgewählten Distributionskanäle über das kommende Hörbuch informiert.
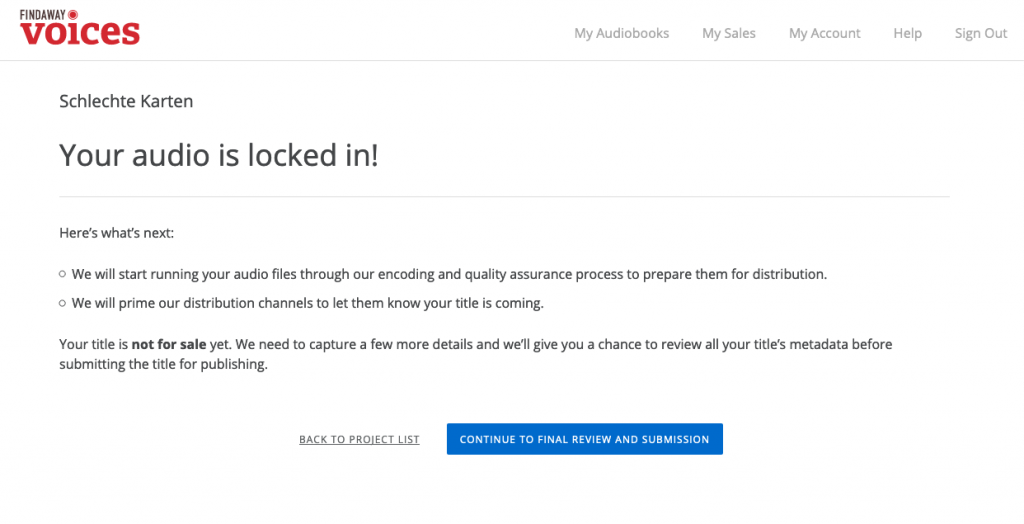
Was da nicht steht ist, dass das jetzt 6 Wochen dauern kann. Deswegen wird einem auch überall geraten, dass wenn man wirklich darauf besteht, dass alle Formate eines Buches am selben Tag rauskommen sollen, man einfach überall auf „publizieren“ klickt, wenn das Audiobuch durch den Prozess durch ist. Hier gibt es einfach noch keine Möglichkeit, den Publikationsprozess zu beeinflussen, einen Wunschtermin anzugeben oder gar Vorbestellungen zu ermöglichen.
Distribution
Für den Verkauf des Hörbuchs kann man sich aussuchen, über welche Kanäle es angeboten werden soll. Nach dem Upload bekommt man die Möglichkeit, sich anhand des Genres und der tatsächlichen Länge einen Preisvorschlag machen zu lassen. Das habe ich auch getan und biete das Hörbuch jetzt für 9.95 an – allerdings in Dollar. Andere Währungen kann FindawayVoices leider nicht. Kobo hat letzte Woche gerade verkündet, jetzt auch den Upload von Hörbüchern direkt zum eBook einzuführen. Bei Kobo hat man dann auch die Möglichkeit, Preise nach Märkten/Währungen anzugeben. Allerdings ist diese Option momentan nur im englischsprachigen Raum verfügbar. Das sollte aber wohl noch Ende des Jahres kommen. Und dann wäre es interessant, Kobo (und die durch Kobo bespielten Kanäle/Handelsplattformen) bei der Distribution bei FindawayVoices abzuhakeln und für den Europäischen Markt via Kobo direkt anzubieten.

ISBN & Metadaten
Ich hatte vor dem Sommer einen ISBN-Bllock gekauft und für die Hörbücher habe ich auch welche daraus vergeben. Das ist bei den Metadaten möglich, die man sorgfältig prüfen und überarbeiten sollte. Grundsätzlich zieht FindawayVoices die Metadaten aus den Informationen, die man bei Draft2Digital angegeben hat, aber ein Blick darauf kann trotzdem nicht schaden.
Im Tab „Metadata“ kann man auch das Hörbuch Cover ersetzen; standardmäßig übernimmt es auch das eBook Cover von Draft2Digital. Zu beachten ist, dass Hörbücher ja immer nur so streichholzschachtelgroß auf den Plattformen angezeigt werden. Also nicht zu kleine Details, eher plakativ denken. Zum anderen gehört auf das Cover alles drauf, was man auch in den Opening Credits drin hat: Titel, Autor*in & Sprecher*in. Größe sollen 3.000×3.000 Pixel sein – also das, was man von iTunes schon vom Podcast Cover kennt.
Fazit
Nachdem ich es geschafft hatte, die 23 Dateien von „Paula1“ endlich (!!!) hochzuladen und auf „abschicken“ zu klicken, ahbe ich sofort noch den Kurzkrimi hinterher geschoben, den ich vor dem Camp auch noch eingesprochen hatte. Die Filter waren jetzt schon im Reaper drin, die Seite zum Hochladen geöffnet und ich innerhalb von knapp 2 Stunden mit allem durch. Lesezeit des Kurzkrimis: eine knappe halbe Stunde.
An der Nachbearbeitung von „Paula1“ habe ich inkl. „Supportwartezeiten“ bei Timm und Georg und frustriertem Schmollen fast zwei Wochen gearbeitet. Allerdings habe ich auch noch andere Sachen zwischendurch gemacht, hatte LaunchDay der Paula eBooks und Printbücher, etc. In reiner Arbeitszeit würde ich jetzt schätzen, dass es fünf Tage fast Vollzeit ware. Aber eben mit diversen Umwegen und Problemen, die beim nächsten Mal nicht mehr sein sollten.
Ja, ich werde es trotz aller Mühen im zweiten Teil trotzdem wieder tun, einfach weil ich a) selbst ein audiophiler Mensch bin und b) auf dem englischsprachigen Markt schon überall die Audiowelle zugeschlagen hat, die dann in 2-5 Jahren auch hier aufschlagen wird. Und dann erst anzufangen wäre mir zu mühsam. Momentan ist das ja fast (!) ein Abwasch, wenn ich die Bücher schon neu herausbringe, auch gleich einzusprechen. Ich gehe außerdem davon aus, dass ich beim nächsten Durchgang in der Nachbearbeitung schon deutlich weniger Zeit brauchen werde, weil ich die Fallstricke jetzt schon einmal gesehen habe. Nicht, dass ich nicht glaube, dass neue dazukommen werden …
Ich denke trotzdem, dass es sich lohnt, ein neues Format zu bespielen. Außerdem war das Feedback der Testhörer*innen sehr gut. Und das beflügelt und motiviert ja auch ungemein.
-> Hörbücher selbst aufnehmen – Teil 1: Aufnahme
-> Lorelei King: How to be an Audiobook Narrator (Hörbuch)
-> es gibt zum Hörbuch auch ein „Companion Script“
-> Podcastfolge „Hörbücher produzieren“ mit Markus Stromiedel
-> Reite die Audio-Welle!
***
Die Links zu Amazon, Thomann & Draft2Digital sind Affiliate Links.

